python爬取知乎实例
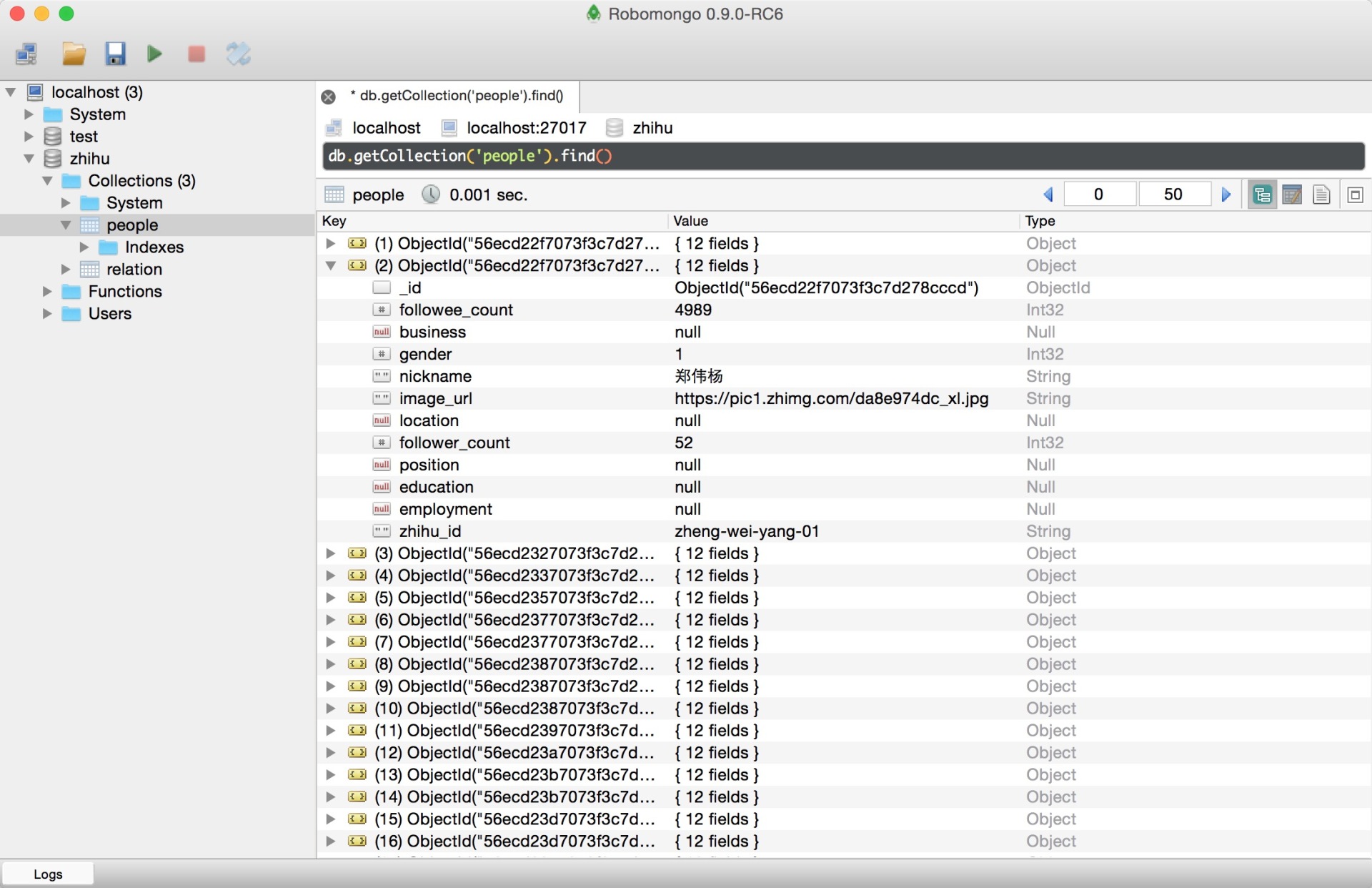
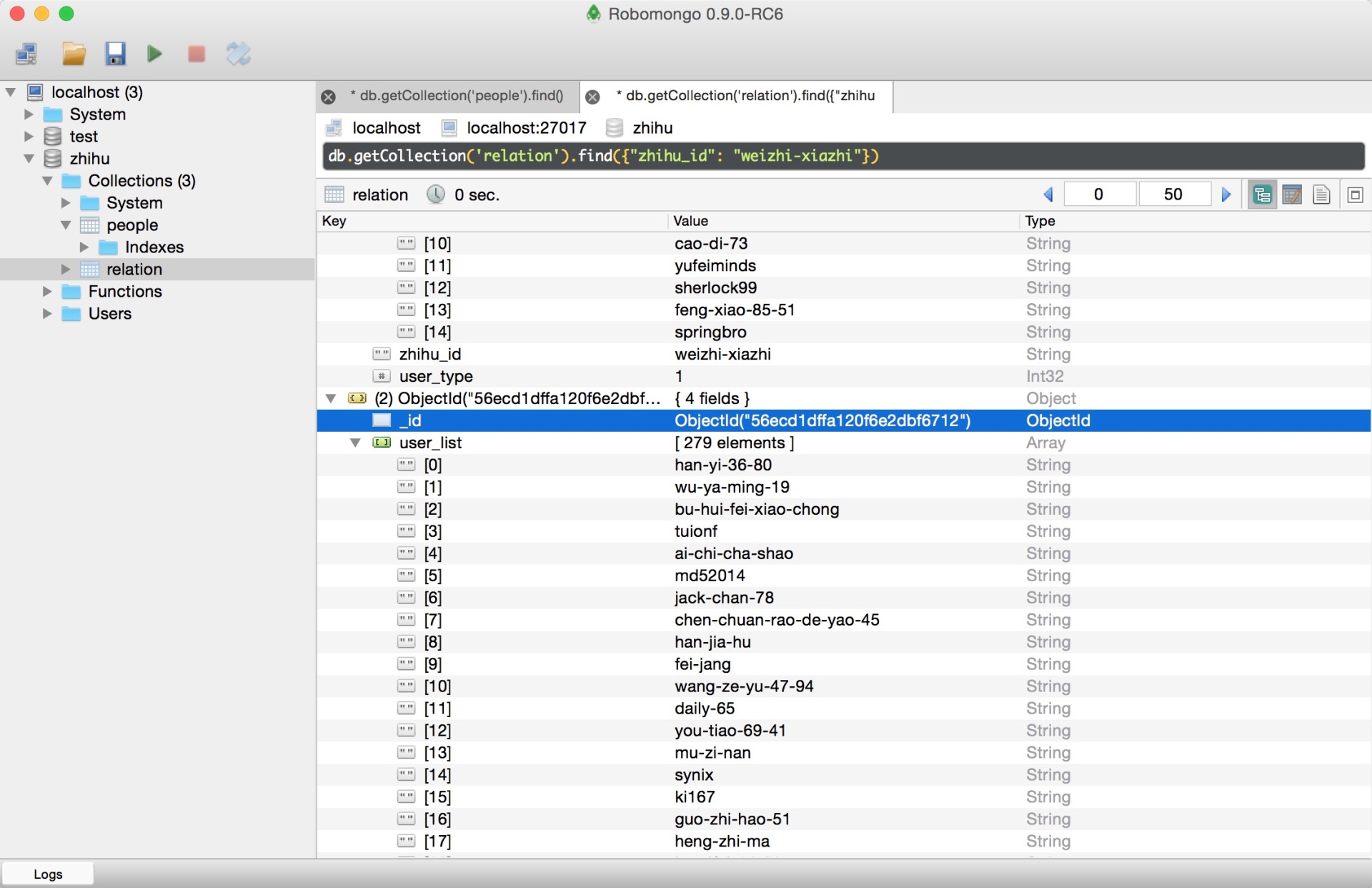
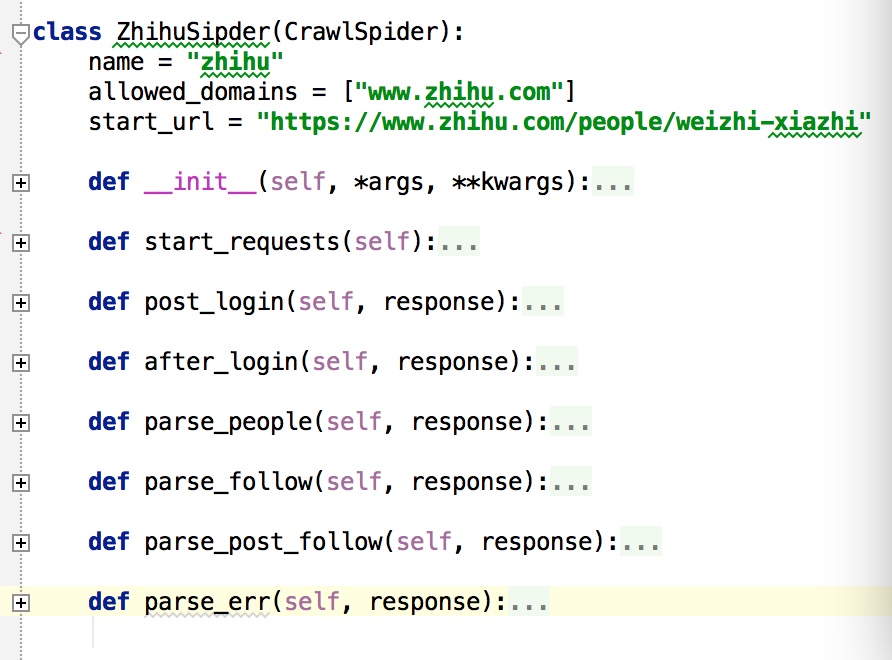
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧。## 使用方法### 本地运行爬虫程序依赖mongo和rabbitmq,因此这两个服务必须正常运行和配置。为了加快下载效率,图片下载是异步任务,因此在启动爬虫进程执行需要启动异步worker,启动方式是进入zhihu_spider/zhihu目录后执行下面命令:

此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧。## 使用方法### 本地运行爬虫程序依赖mongo和rabbitmq,因此这两个服务必须正常运行和配置。为了加快下载效率,图片下载是异步任务,因此在启动爬虫进程执行需要启动异步worker,启动方式是进入zhihu_spider/zhihu目录后执行下面命令: