python爬虫用scrapy获取影片的实例分析
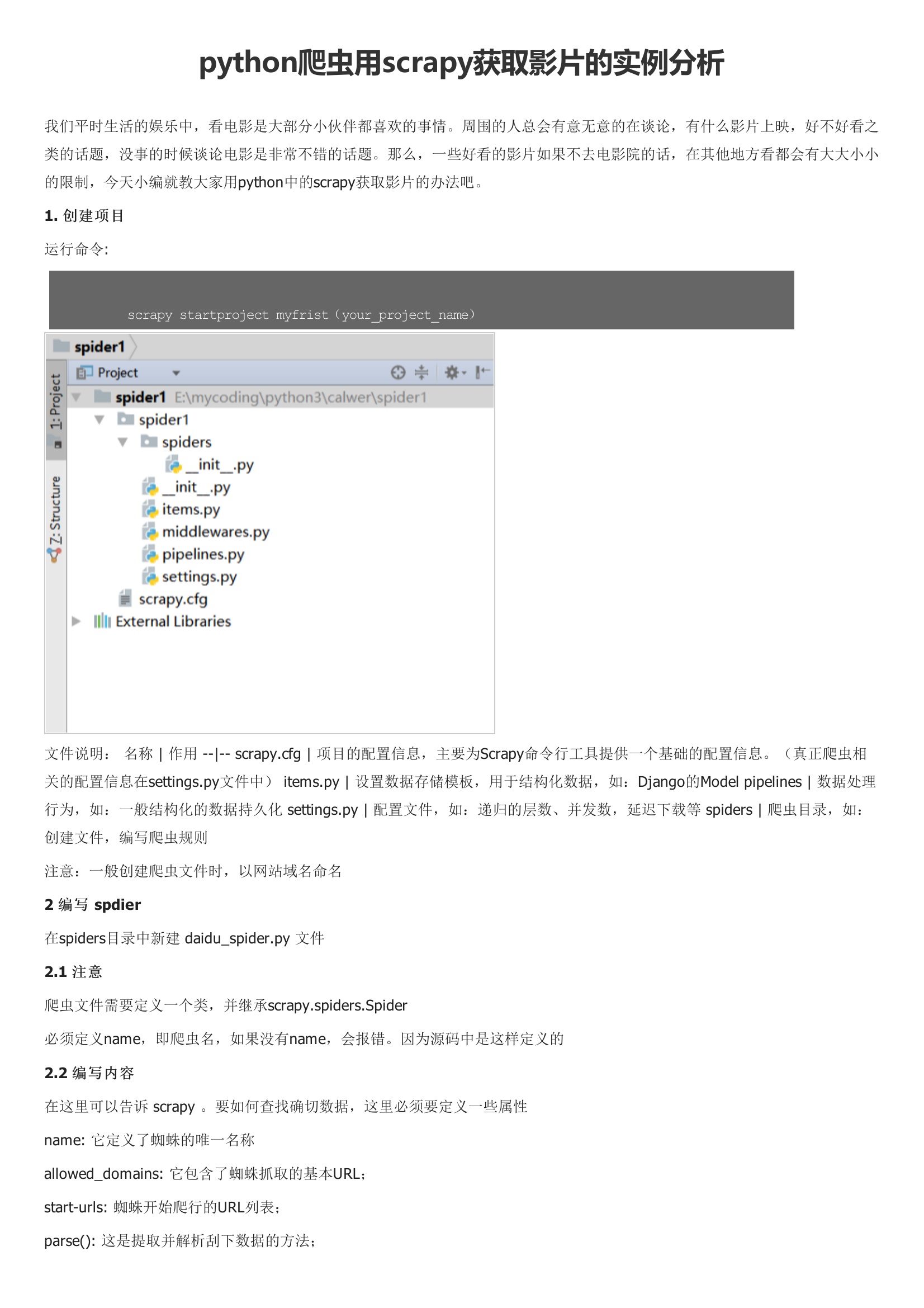
items.py | 设置数据存储模板,用于结构化数据,如:Django的Model pipelines | 数据处理行为,如:一般结构化的数据持久化 settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 spiders | 爬虫目录,如:创建文件,编写爬虫规则注意:一般创建爬虫文件时,以网站域名命名在spiders目录中新建 daidu_spider.py 文件爬虫文件需要定义一个类,并继承scrapy.spiders.Spider必须定义name,即爬虫名,如果没有name,会报错。因为源码中是这样定义的在这里可以告诉 scrapy 。