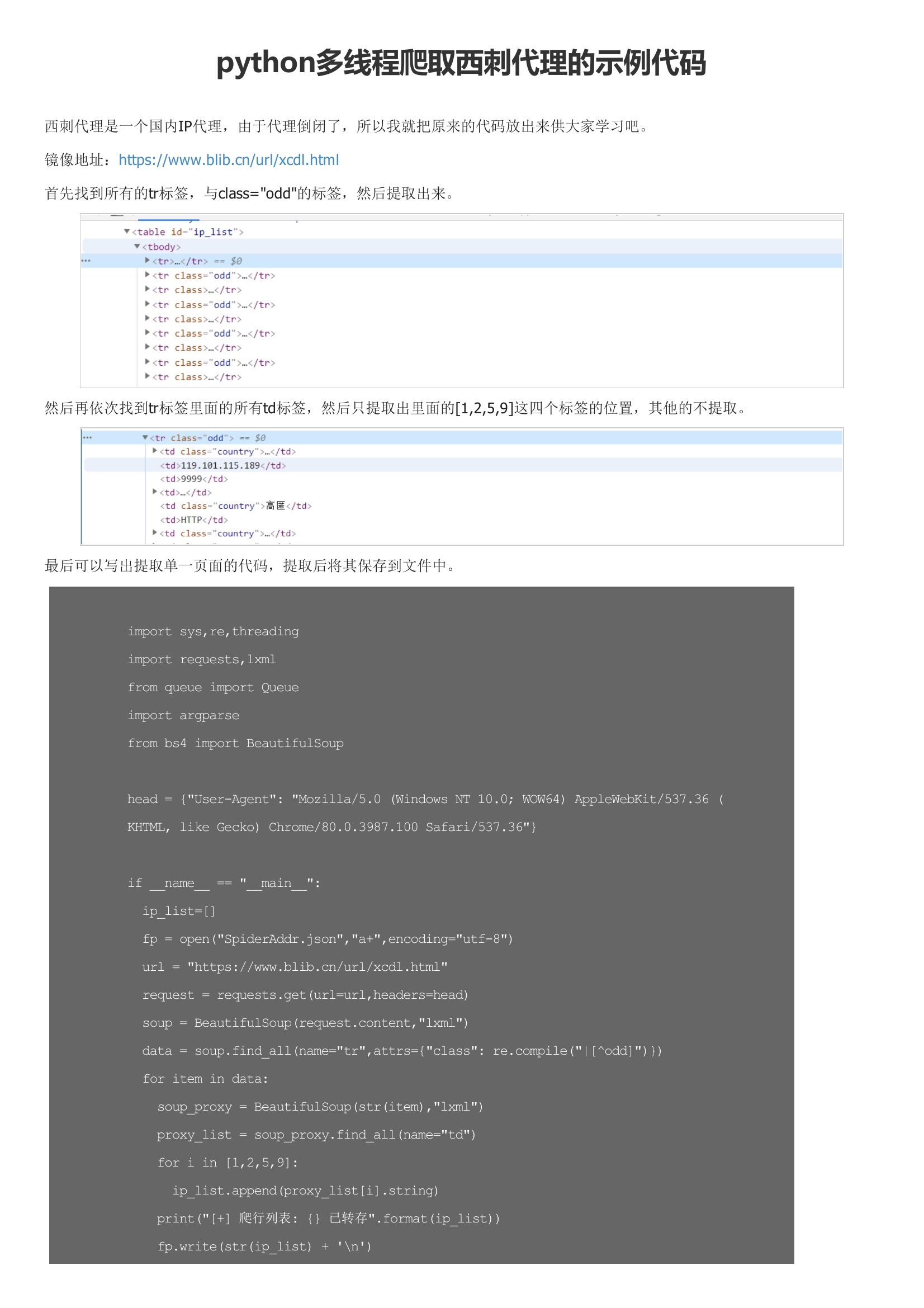
西刺代理是一个国内IP代理,由于代理倒闭了,所以我就把原来的代码放出来供大家学习吧。然后再依次找到tr标签里面的所有td标签,然后只提取出里面的[1,2,5,9]这四个标签的位置,其他的不提取。最后可以写出提取单一页面的代码,提取后将其保存到文件中。爬取后会将文件保存为 SpiderAddr.json 格式。
多线程示例 java
测试平台 Ubuntu 13.04 X86_64 Python 2.7.4 花了将近两个小时, 问题主要刚开始没有想到传一个文件对象到线程里面去, 导致下载下来的文件和源文件MD5不一样,浪费不少时间
该程序实现爬取某代理IP网站的IP列表,可以保存任意页数。具体网址见程序代码。 python新人,多多指教,QQ:403425608
主要介绍了Python利用Scrapy框架爬取豆瓣电影,结合实例形式分析了Python使用Scrapy框架爬取豆瓣电影信息的具体操作步骤、实现技巧与相关注意事项,需要的朋友可以参考下
主要介绍了Python实现爬虫爬取NBA数据功能,涉及Python针对URL模块、字符串、列表遍历、Excel写入等相关操作技巧,需要的朋友可以参考下
多线程扫描代理器是一款代理论坛账号马甲的神器
Multi-threaded ip proxy acquisition
多线程急速代理验证 很不错的源码 打架下载看看吧
仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2)
Python代理抓取并验证使用多线程实现



用户评论