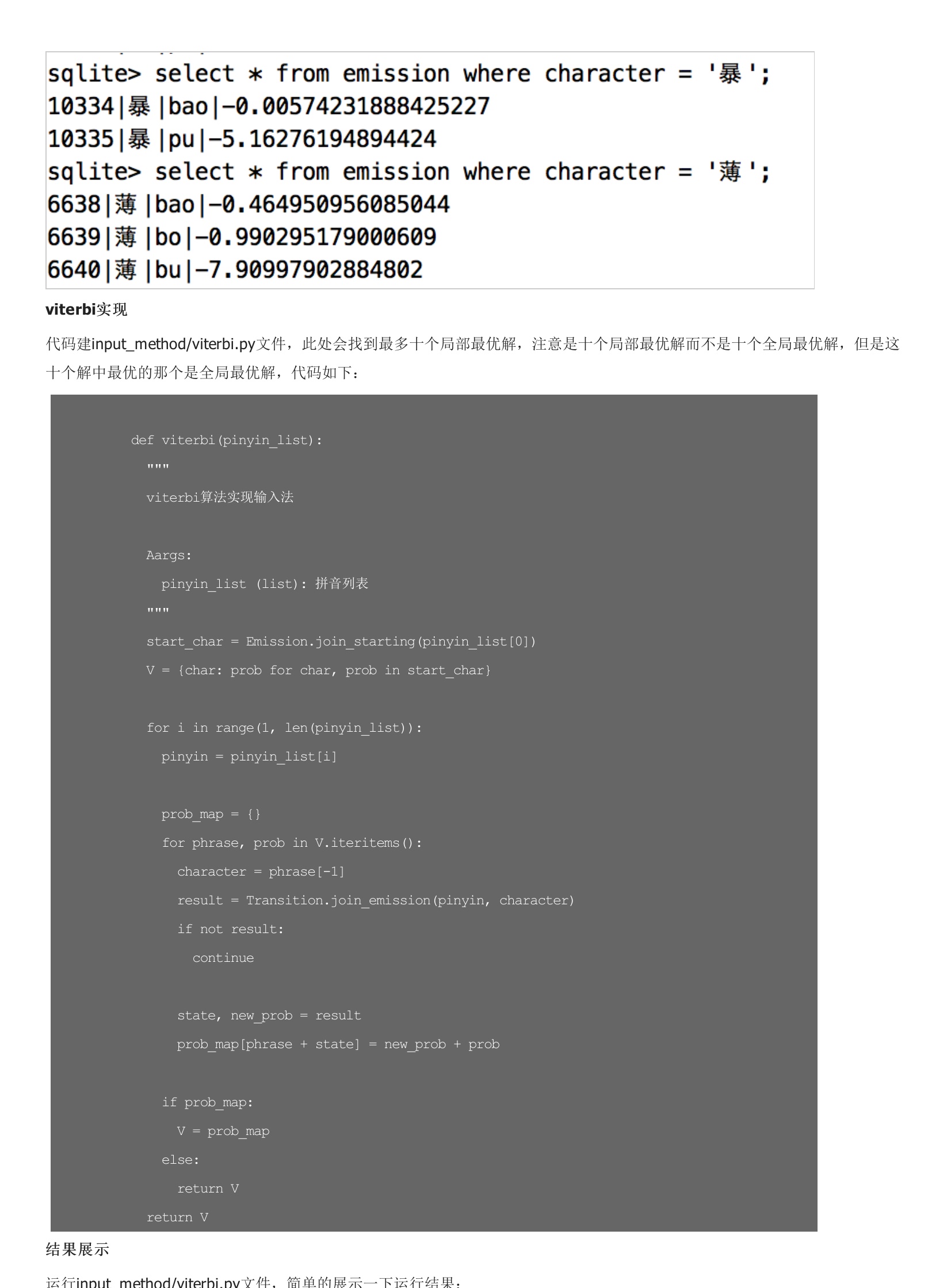
统计的结果如下:此处用到的是最简单的一阶隐马尔科夫模型,即认为在一个句子里,每个汉字的出现只和它前面的的一个汉字有关,虽然简单粗暴,但已经可以满足大部分情况。统计的过程就是找出字典中每个汉字后面出现的汉字集合,并统计概率。此处统计用到了pypinyin模块,把字典中的短语转换为拼音后进行概率统计,但是某些地方读音也不完全正确,最后运行的输入法会出现和拼音不匹配的结果。发射概率矩阵数据不准确,总有一些汉字的拼音不匹配。
暂无评论
文件中包含多个数据示例,有GMHMM的示例进行A,B,PI的估计。有股票数据的训练预测
HMM隐马尔科夫模型的C++实现,很全哦,相信对你的学习有帮助>
这是关于HiddenMarkovModel的一个实现,非常好用。
本程序利用OpenCV实现了基于隐马尔科夫模型的人脸识别,代码简洁明了
基于隐马尔科夫模型的词性标注,PPT,详细描述
传统检测方法很难及时辨别出DDoS攻击的种类与方式,针对这一问题,基于隐马尔可夫模型研究了一种新的多级残差网络DDoS攻击检测方法。该检测方法可以在DDoS攻击多级残差网络时,应用相关公式提取DDoS
引入改进的隐马尔可夫模型算法,针对真实场景中运动目标轨迹的复杂程度对各个轨迹模式类建立相应的隐马尔可夫模型,利用训练样本训练模型得到可靠的模型参数;计算测试样本对于各个模型的最大似然概率,选取最大概率
基于隐马尔可夫模型挖掘移动对象轨迹模式,周昊维,,现有的时空模式发现方法都将数据空间划分成不相交的单元来进行有效的处理。然而,空间划分方法的发现精度极大地依赖于空间粒度,
基于隐马尔可夫模型的网络状态分析方法,范士明,廖述剑,目前基于模式匹配的网络入侵检测系统(NIDS),一般都是直接处理网络数据流,而网络中恶意流量通常只占据1%以下,面对网络中的数据海�
基于隐马尔可夫模型的人脸识别C/C++源代码


暂无评论