暂无评论
这学期学校开了数据挖掘这门课,然后花了几天时间Python入门,老师不打算讲爬虫这一块,自己对爬虫一直挺感兴趣,想了解一下,所以用了两天简单的学了一下爬虫,做了一个小demo 目标网站: http:/
可转至我的博客http://www.dwlufvexyu.com/python-selenium爬取斗鱼/看 csdn我没排版 不加延迟报错selenium.common.exceptions.NoS
python使用requests模块请求网址,使用lxml模块中etree抓取数据,并使用time模块延时 爬取斗图啦如图所示: 将爬取到每页的数据保存在文件夹中 打开任意一个文件,将图片保存在内:
本案例仅供学习参考,请大家不要实时运行以免影响企业正常运行。 可以爬取美团美食的所有店铺,使用说明,一个城市的真实爬取好的数据以及token解析工具。爬取的数据会存入excel,程序会自动建立exce
用python爬取捧腹网,听锁薇老师讲爬虫,获取你想要的数据!
简单,易懂,容易上手,适合初学者。python版本使用的python3,BeautifulSoup需要安装
利用Python的Requests和BeautifulSoup第三方库爬取zol壁纸网站上分辨率为1920x1080的图片,使用者可选择爬取的壁纸类别,在根目录的pic下分类保存壁纸。 使用方法:直接
python爬取煎蛋网xxoo图自己写的小程序
通过Python中的re、BeautifulSoup、threading模块,实现对笔趣阁网站小说的批量读取,zip中仅包含Python源码。
利用python爬取网站上面的历史天气,并且使用正则表达式针对于网站上面的数据进行获取,最后生成excel表格
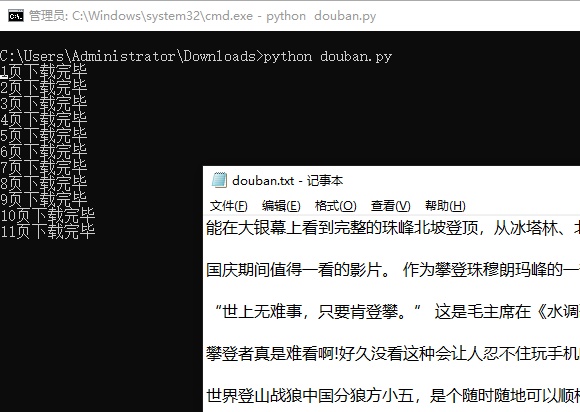
暂无评论