适合爬虫初学者的必备入门demo,效果如下:
要求环境python3.7,安装库
requests,xlwt,re,os
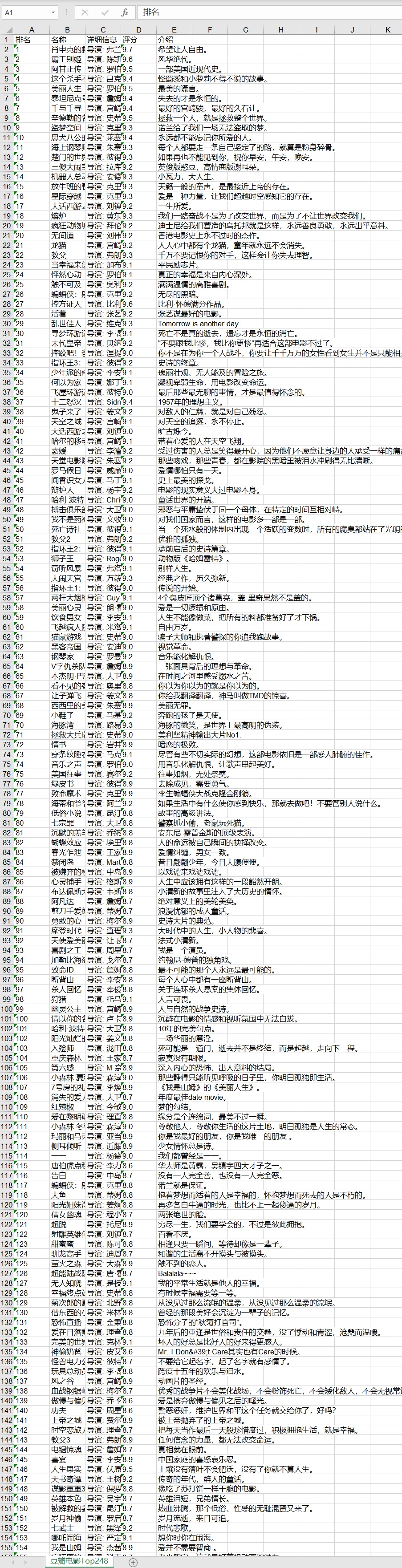
采用新手友好的原始正则对文本进行筛选,爬取豆瓣top250电影信息,生成excel表格,可在pycharm中直接运行,
默认保存目录D:/test
暂无评论
豆瓣电影250爬虫史诗增强版
豆瓣Top250Python爬虫+数据可视化.zip
以下是一个关于如何使用Python编写爬虫来爬取链家网站的源码案例。通过这个案例,你可以学习到如何利用Python中的相关库和技术,对链家网站上的房产信息进行爬取和提取。源码中包含了爬虫的基本结构、请
精心整理2020年热门高分电影TOP250名录,包含电影名称,导演,年份,类别,评语,海报图等字段,可下载应用于数据库基础数据构建上层应用,数据格式为json,noSql数据库可以直接导入,sql数据
名称我不是药神评分9.6排名1主演徐峥周一围王传君上映时间20180705名称肖申克的救赎评分9.5排名2主演蒂姆罗宾斯摩根弗里曼鲍勃冈顿上映时间19940910加拿大名称海上钢琴师评分9.3排名3主
本教程将详细介绍如何使用Python爬虫爬取Top100电影榜单数据并保存为csv文件。我们将介绍开发工具、所需模块、操作步骤及网址解析等内容。适合Python初学者学习和参考。需要源码的读者可以在本
Python爬取猫眼豆瓣数据,生成大数据海报
python爬取豆瓣租房信息
轻量级的网页爬取,对著名网站豆瓣进行初试;对python进阶以及爬虫入门有着教学性作用,对python3中requests,re等模块进行尝试
文章目录一、需求二、分析三、Code准备工作main.pyspider.py 一、需求 使用任意代理 IP 进行如下操作 使用requests模块进行豆瓣电影的个人用户登录操作 使用requests模
暂无评论