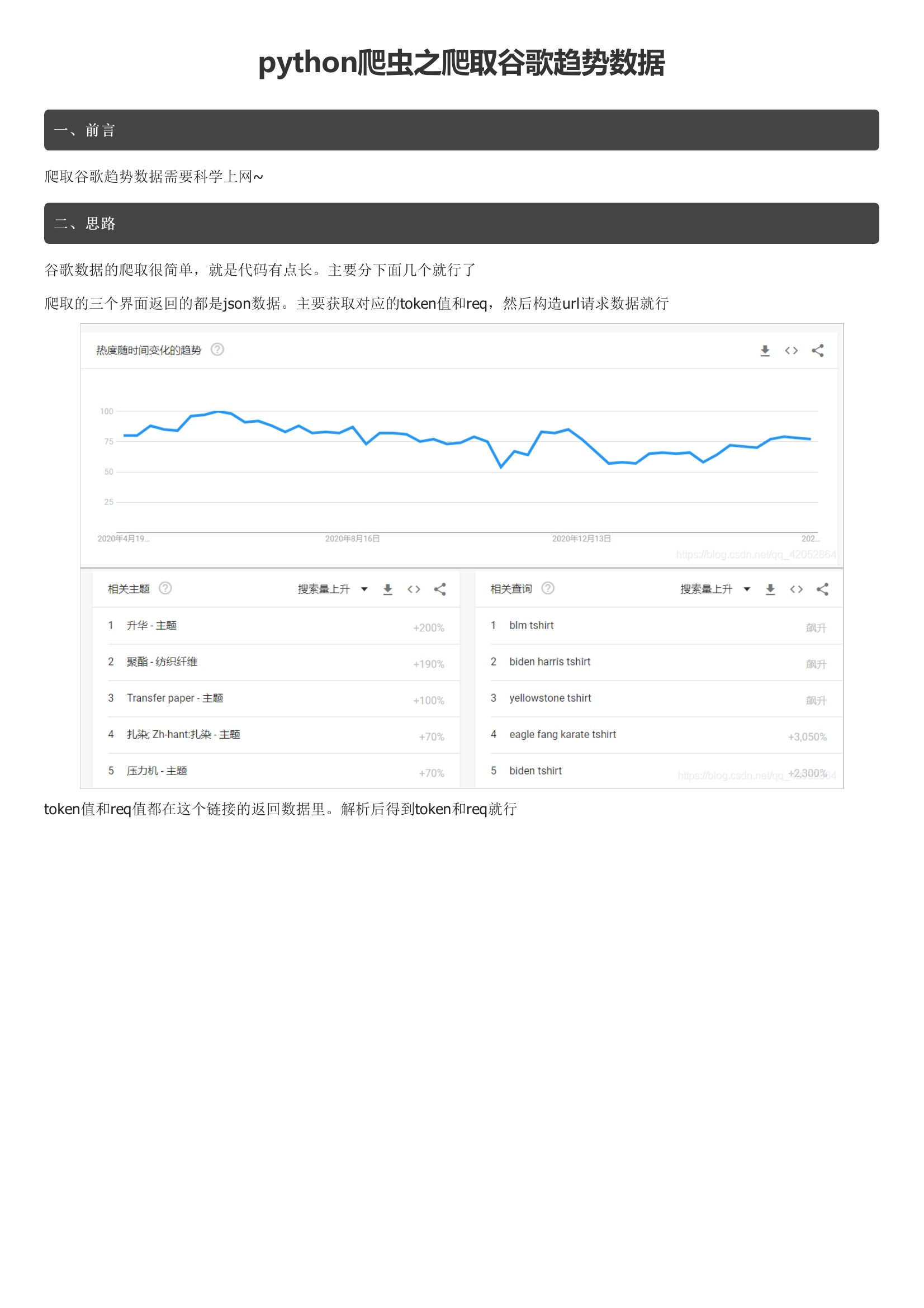
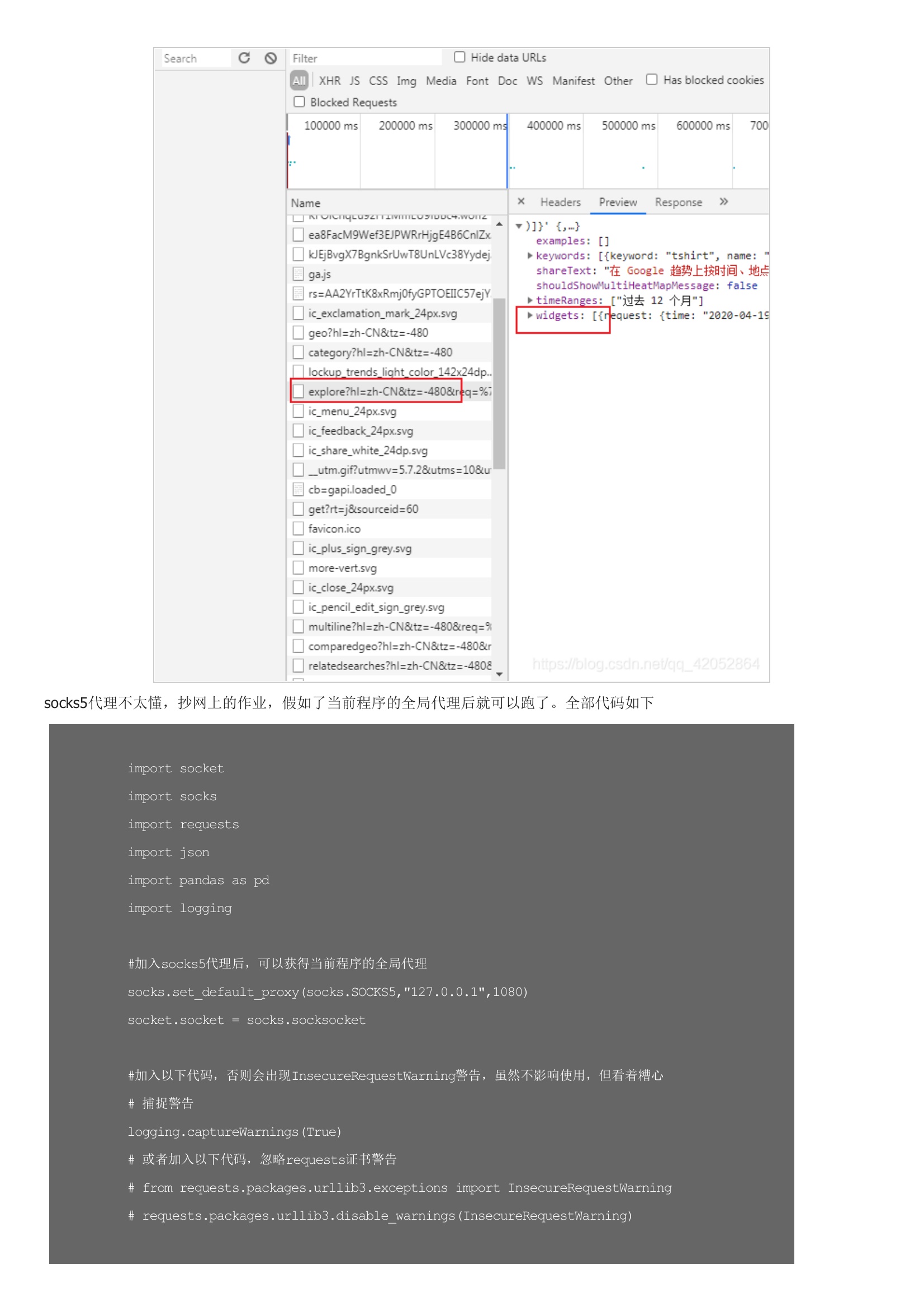
python爬虫之爬取谷歌趋势数据
暂无评论
python爬虫爬取文字生成TXT文件通过MAIN文件运行使用pycharm2021.3.2版建议更换网址后爬取不适合作为作业提交参考格式的话还是没问题的.
1数据描述数据来源豆瓣最受欢迎的影评数据获取豆瓣最受欢迎的影评并将获取的这些信息评论链接电影名电影详细地址评论标题以及评论地址等写入excel表格同时也会生成词云.2数据获取步骤第一步调用获取页面信息
使用python爬取蚂蚁网的小说供学习使用https www.mayiwxw.com使用环境PyCharm输入蚂蚁网中小说的第一章网页地址即可获取整本小说可以自定义存储位置
通过python程序爬取正方教育管理系统,运行爬虫,按提示输入学校教务网,用户名,密码,输入验证码爬取个人课表,成绩绩点等信息生成txt
以下是一个关于如何使用Python编写爬虫来爬取链家网站的源码案例。通过这个案例,你可以学习到如何利用Python中的相关库和技术,对链家网站上的房产信息进行爬取和提取。源码中包含了爬虫的基本结构、请
爬虫项目,爬取小说,爬取京东手机
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一
代码较为完整,利用python2.7+acaconda编写,爬取美团商家名称,商家地址,商家电话,商家经纬度,并写入excel表中,最新可直接运行。
使用beautifulsoup爬取网站评论,,个人信息等(python代码)。
爬虫文件(Python实现)[爬取的成都所有房价]-爬取的数据文件(txt文件,空格分隔)[成都所有房价信息]-分析的文件(Python实现)(pandas+numpy+matplotlib分析)-简




暂无评论