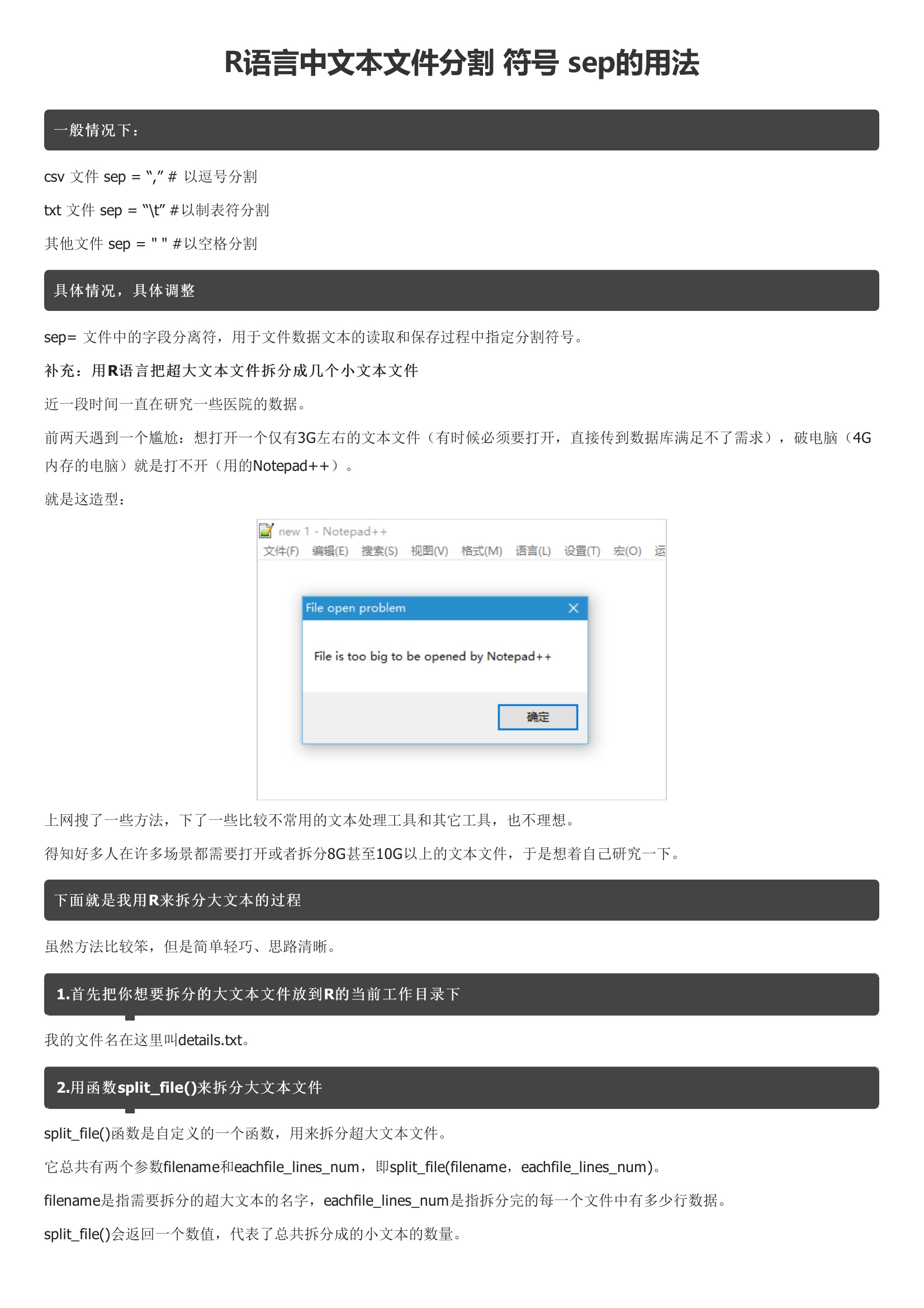
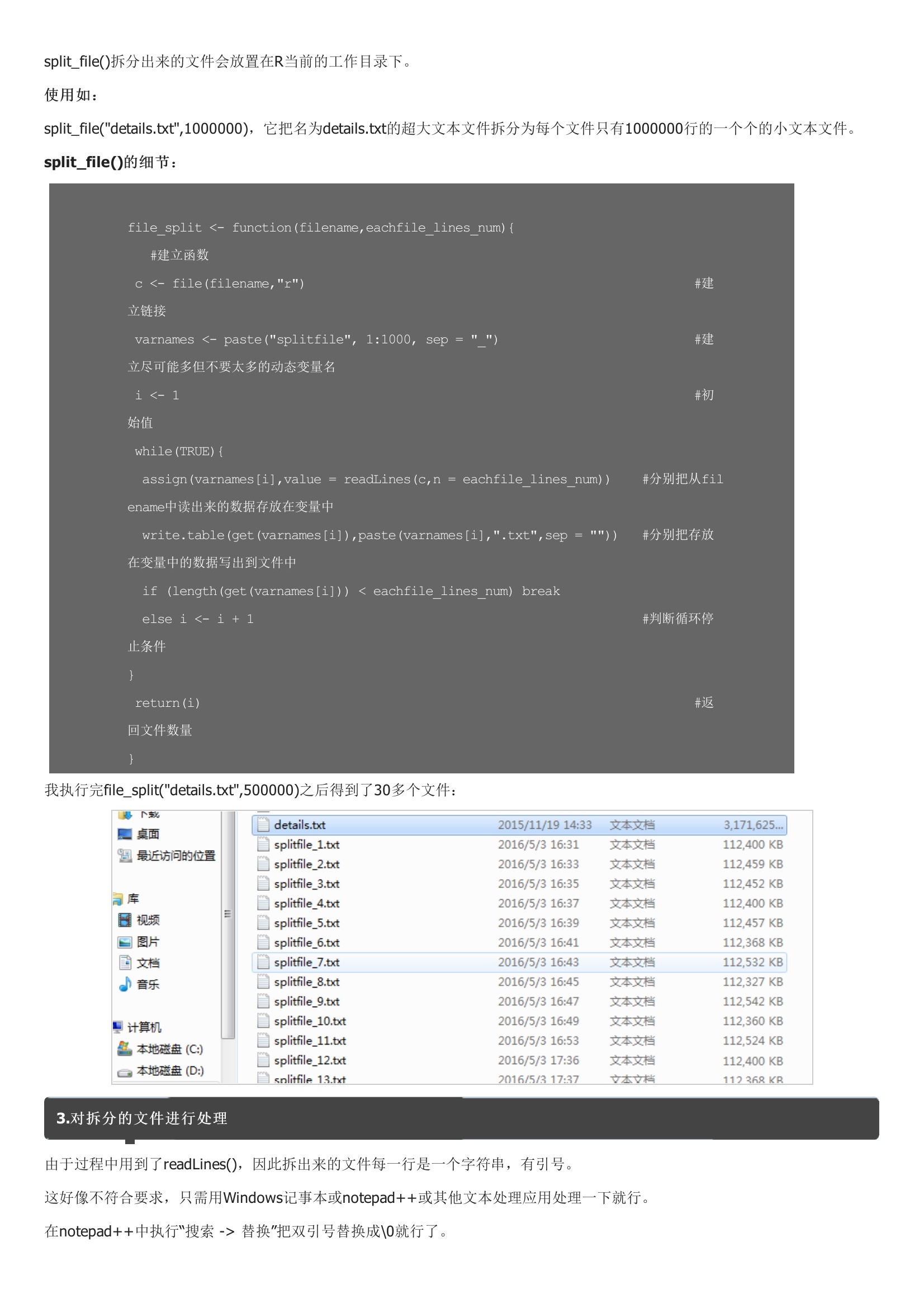
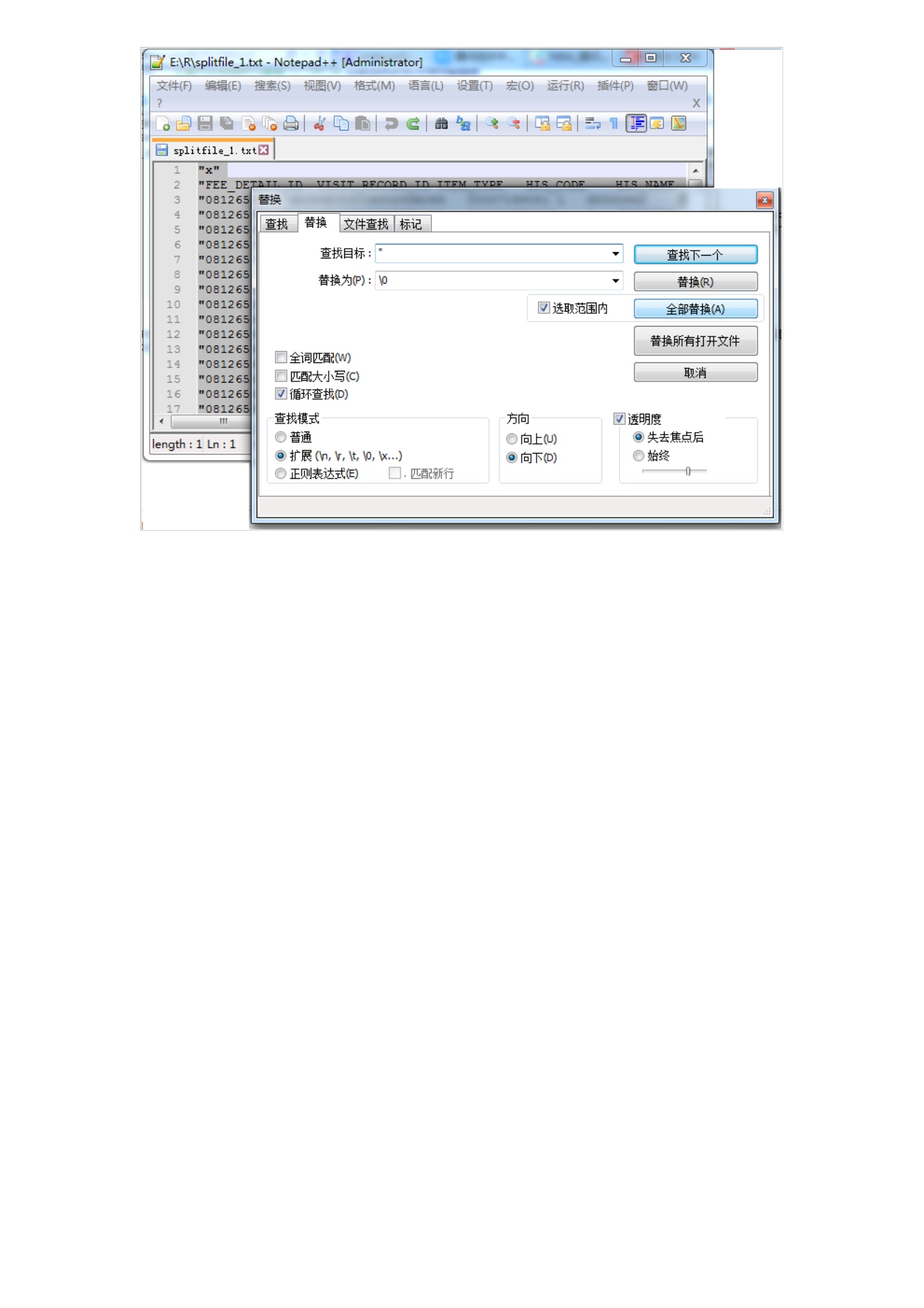
近一段时间一直在研究一些医院的数据。它总共有两个参数filename和eachfile_lines_num,即split_file。filename是指需要拆分的超大文本的名字,eachfile_lines_num是指拆分完的每一个文件中有多少行数据。split_file()会返回一个数值,代表了总共拆分成的小文本的数量。split_file()拆分出来的文件会放置在R当前的工作目录下。split_file,它把名为details.txt的超大文本文件拆分为每个文件只有1000000行的一个个的小文本文件。我执行完file_split之后得到了30多个文件:3.对拆分的文件进行处理由于过程中用到了readLines(),因此拆出来的文件每一行是一个字符串,有引号。这好像不符合要求,只需用Windows记事本或notepad++或其他文本处理应用处理一下就行。在notepad++中执行“搜索 -> 替换”把双引号替换成\0就行了。
暂无评论