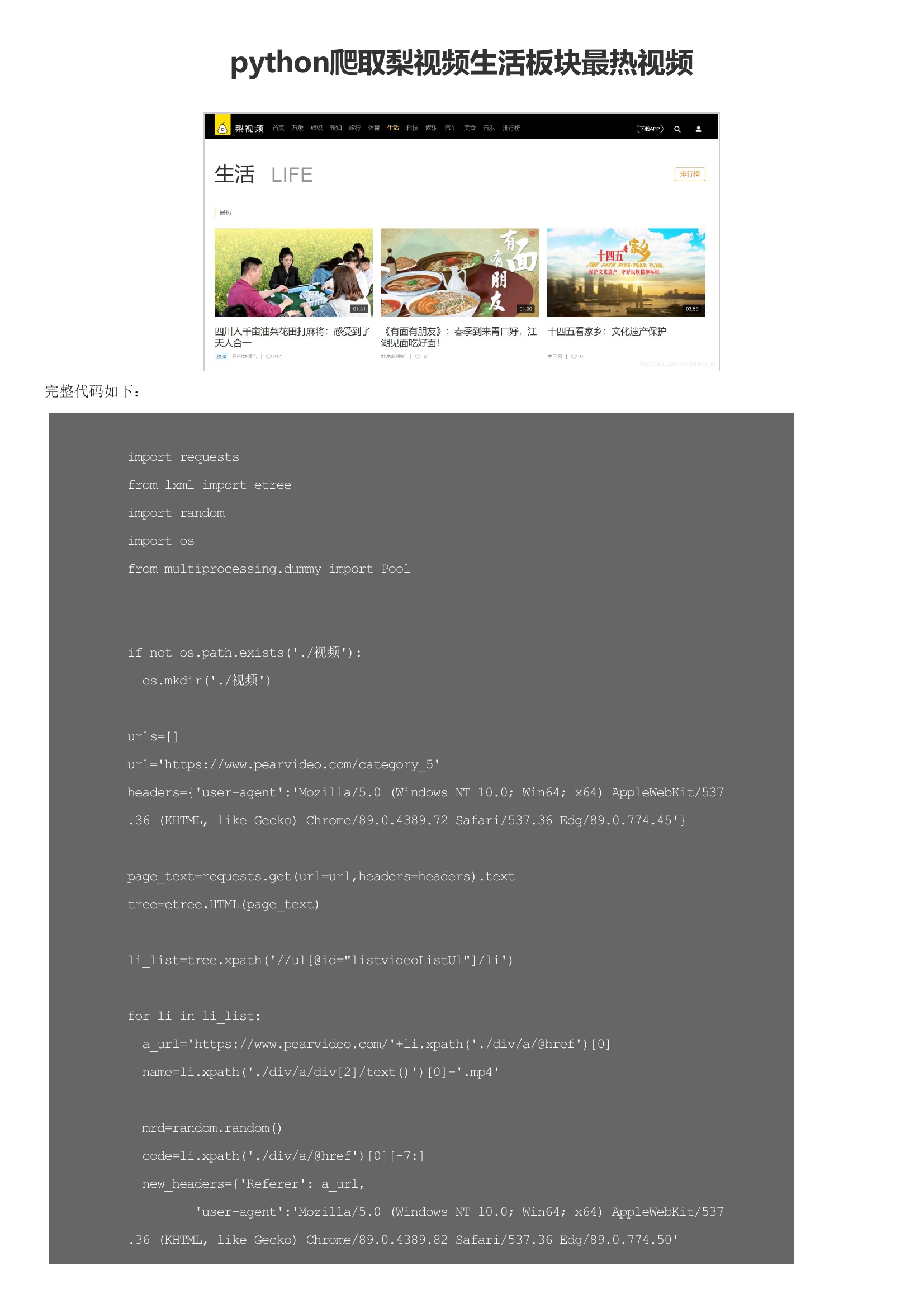
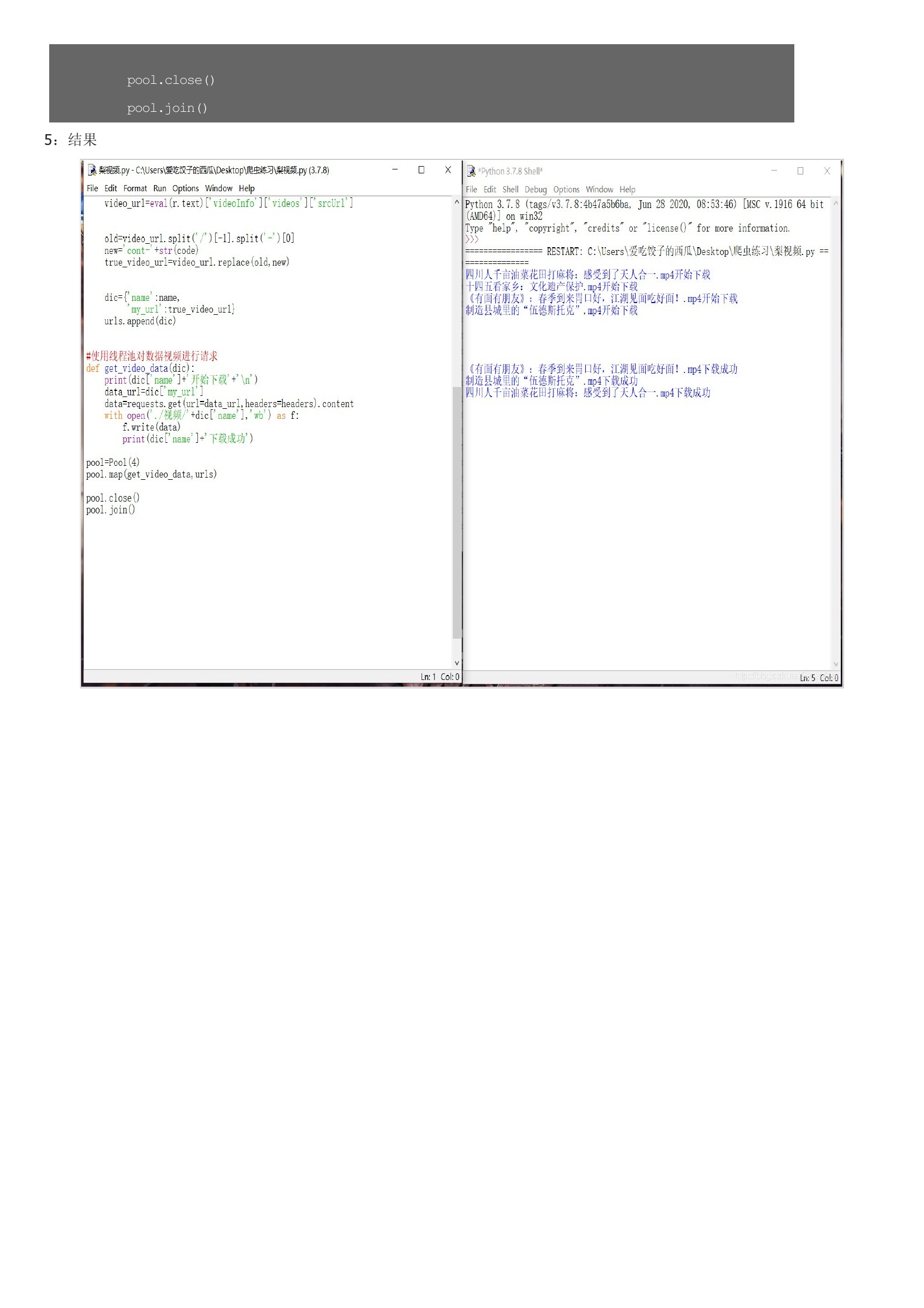
部分代码解释:1:模块2:获取视频伪url3:获取真正url经本人实验,使用上文获得的url爬取视频下载内容为空。由于本人也是菜鸟,所以百思不得其解,恰巧看到B站用户”_千户”的留言才得知真伪url的差异:此处视频地址做了加密即ajax中得到的地址需要加上cont-,并且修改一段数字为id才是真地址4:存储5:结果
暂无评论
python爬取豆瓣租房信息
思路 改进原博主文章(Python GUI–Tkinter简单实现个性签名设计)的代码,原先的代码是基于Python2的,我这份代码基于Python3 并针对当前的网站做了相应调整 前置要求 Pyth
说明:寒假任务是做一个带UI界面的天气预报软件,先上最终结果图。 其中用到的知识有:python网络爬虫、python的xlwt和xlwd库的使用,PyQt5的使用。 这里分享一下完成过程: 制作UI
本文实例为大家分享了python实现爬取图书封面的具体代码,供大家参考,具体内容如下 kongfuzi.py 利用更换代理ip,延迟提交数据,设置请求头破解网站的反爬虫机制 import reques
使用高德api进行对指定中心点的矩形范围内的公交路线经纬度和站点进行爬取,适用于交通态势数据爬取
python爬虫爬取小说并入库安装数据库驱动pip install pymysql数据库连接池pip install DBUtils建表CREATE TABLE novel id int1
可从fabiaoqing上分页爬取表情图,非常简单的代码,适合新手玩玩,注意不要弄太多页,容易被服务器检测到,然后短时间无法访问。
Python爬虫入门之爬取360翻译,通过分析36翻译的网络请求,利用Python的requests模块爬取,代码简单,入门级别,适合初学者学习。
使用selenium加载网页,回去网页源代码,爬取天天基金网站基金排行,并存储在MongoDB和txt几十本中。
IDE使用的是VS2015自己学习了一段时间Python的基础知识后,编写的从网上爬取的世界港口数据,并存储到SQLServer数据库中。如果在使用的时候发现引用库无法识别,先将这些库注册一下,注册


暂无评论