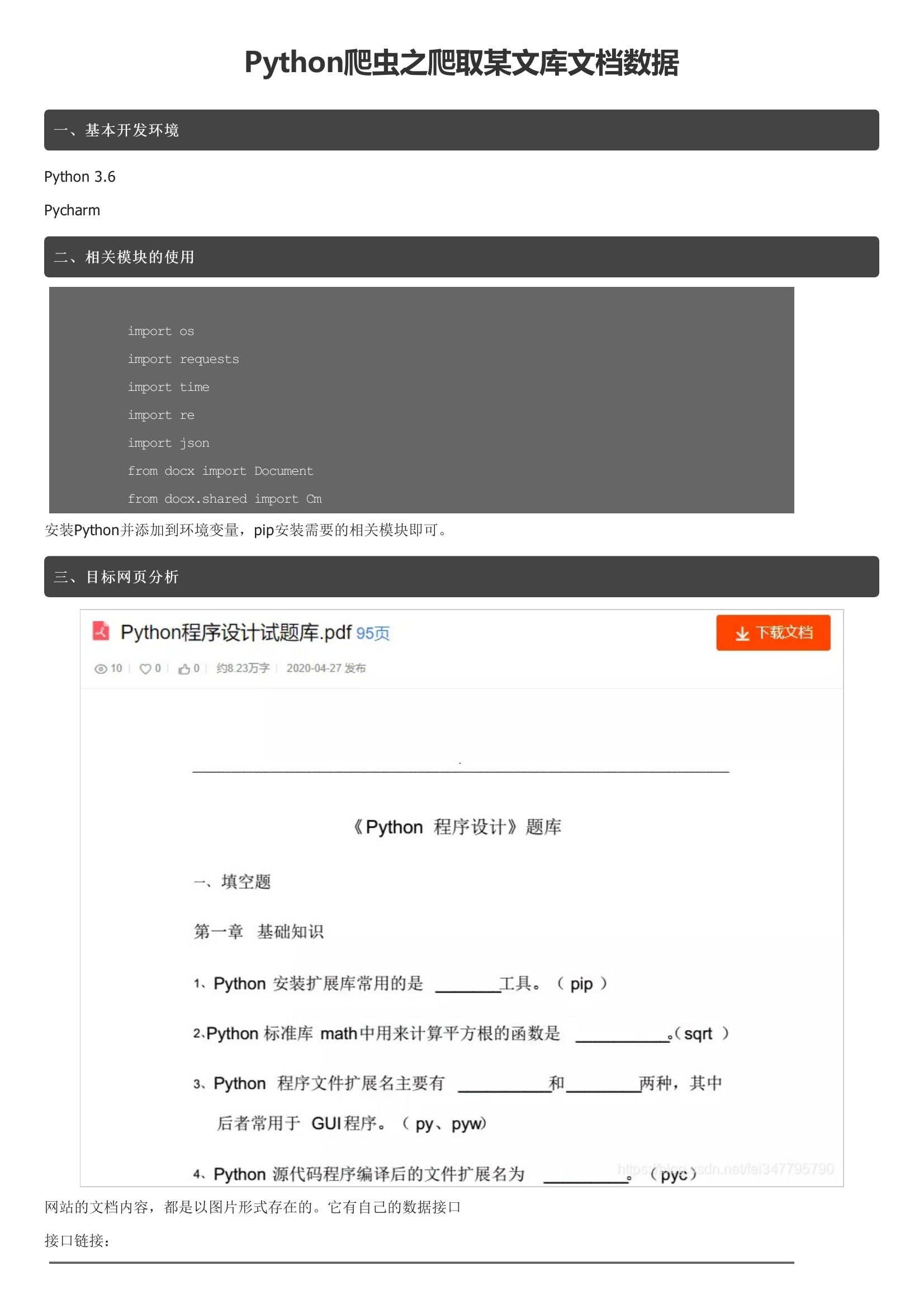
它有自己的数据接口接口链接:接口的请求参数四、整体思路
暂无评论
Python web crawler - crawling Sina News Consulting
使用python语言,通过爬虫技术,爬取qidian小说数据的源码。python爬虫学习的必备技能,从这里开始。
网络爬虫从一个或若干初始网页的URL开始获得初始网页上的URL在抓取网页的过程中不断从当前页面上抽取新的URL放入队列直到满足系统的一定停止条件.聚焦爬虫的工作流程较为复杂需要根据一定的网页分析算法过
python爬虫爬取网易云音乐评论
简单的盗墓笔记爬取,单纯的使用urllib,正则表达式做的,是urllib3的版本,使用基于anaconda的python3.5版本,做一个实验性质的小爬虫,供大家参考
python爬虫爬取文字生成TXT文件通过MAIN文件运行使用pycharm2021.3.2版建议更换网址后爬取不适合作为作业提交参考格式的话还是没问题的.
1数据描述数据来源豆瓣最受欢迎的影评数据获取豆瓣最受欢迎的影评并将获取的这些信息评论链接电影名电影详细地址评论标题以及评论地址等写入excel表格同时也会生成词云.2数据获取步骤第一步调用获取页面信息
使用python爬取蚂蚁网的小说供学习使用https www.mayiwxw.com使用环境PyCharm输入蚂蚁网中小说的第一章网页地址即可获取整本小说可以自定义存储位置
Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以
python爬虫爬取微博热搜



暂无评论