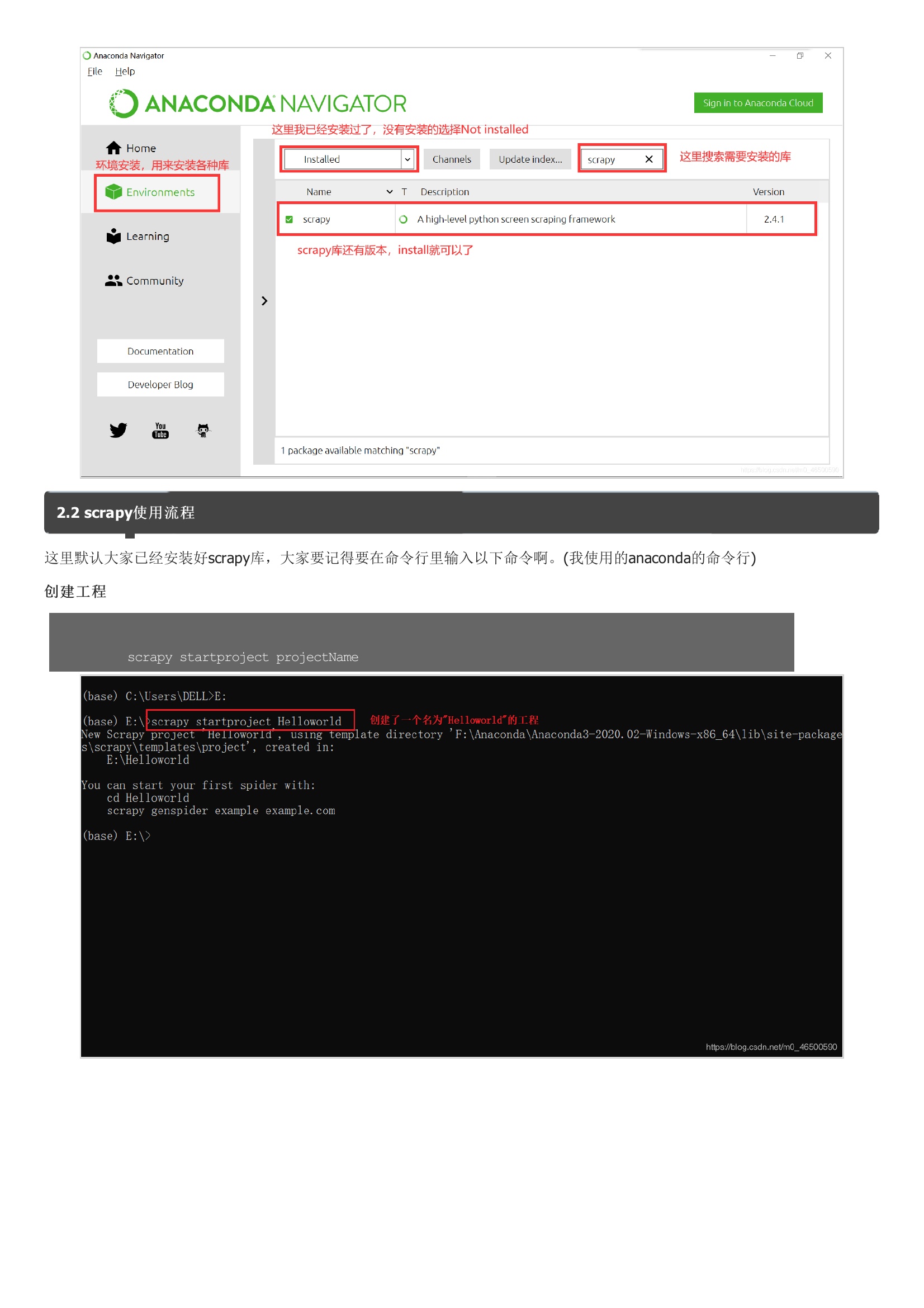
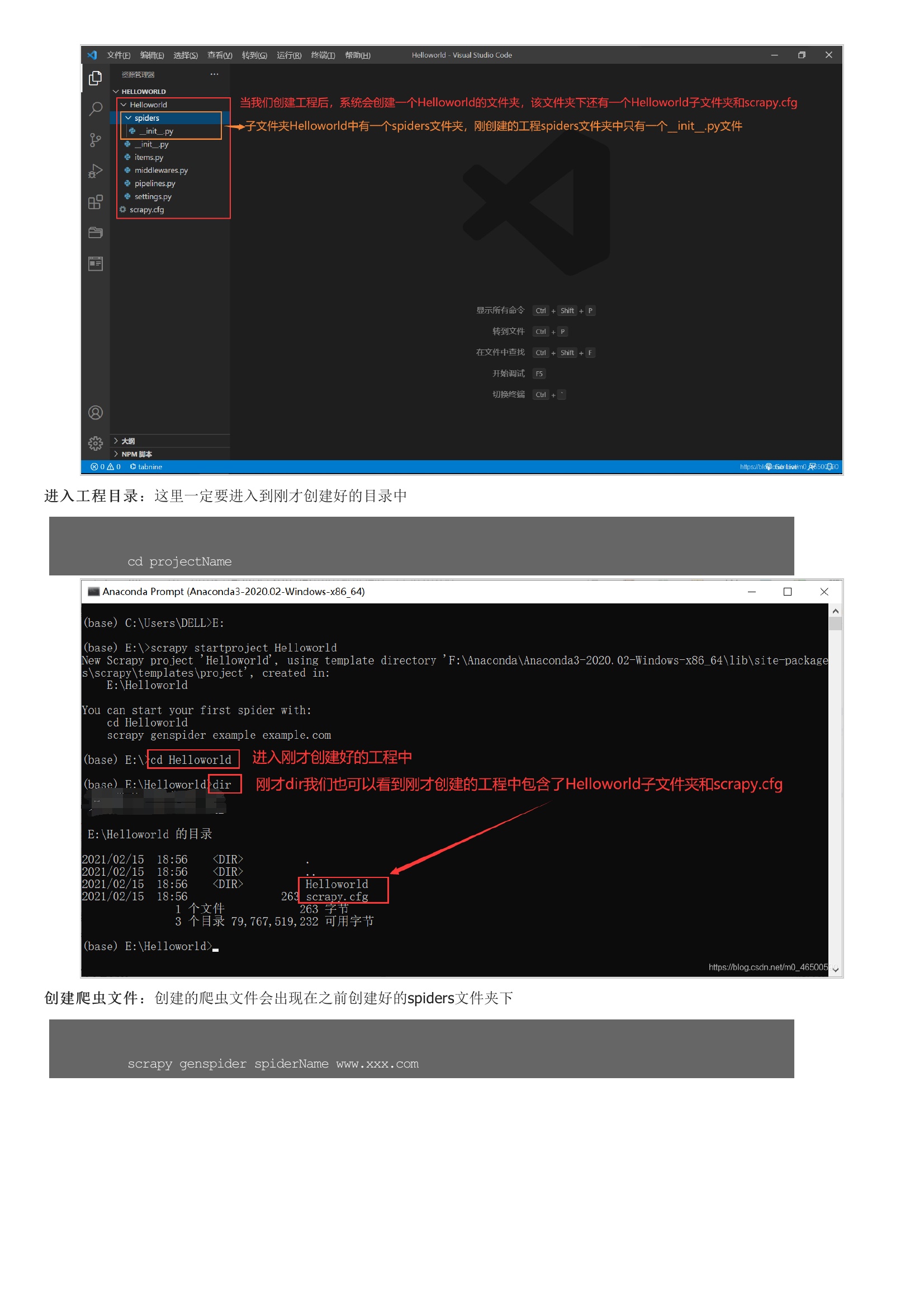
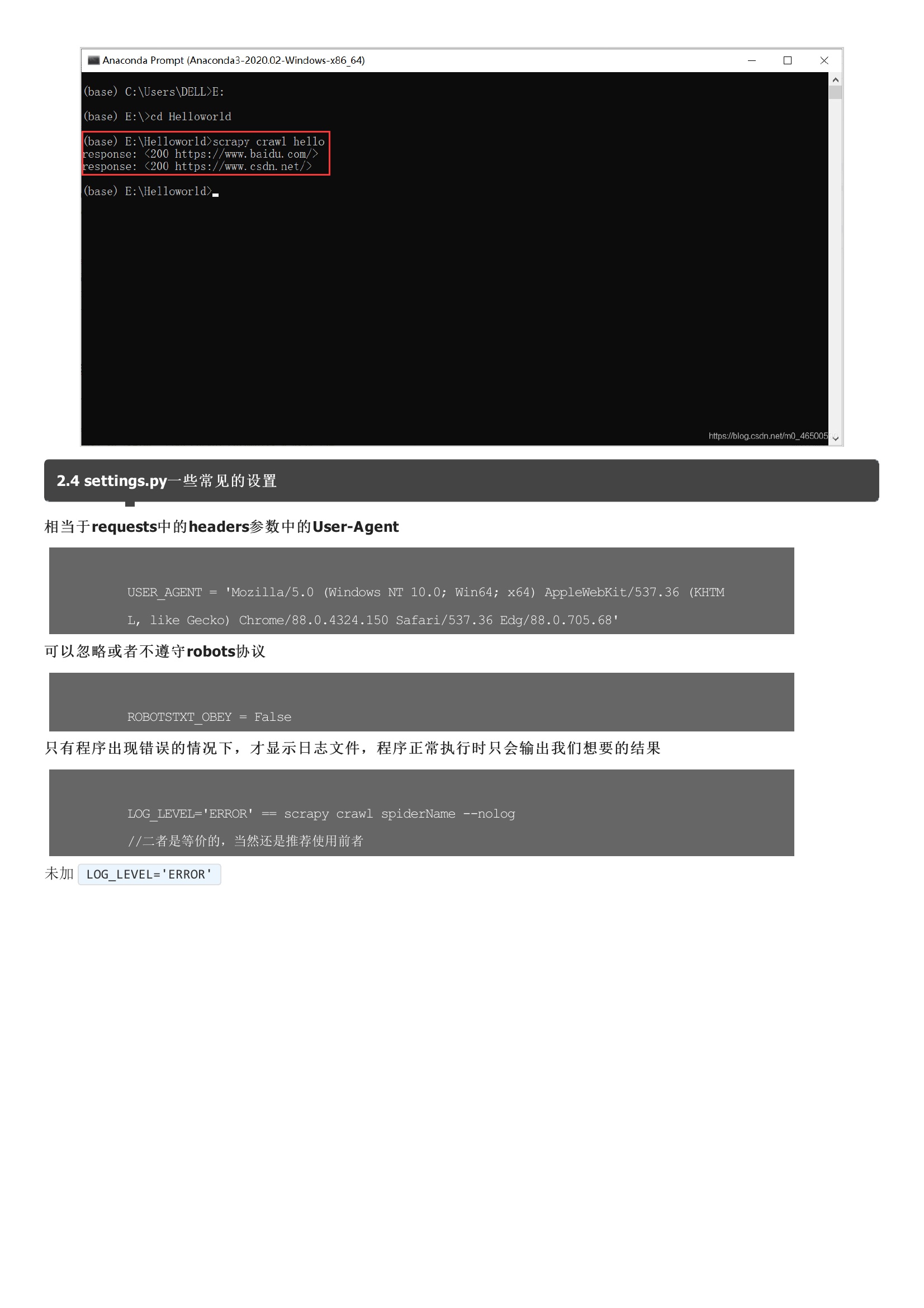
在我一开始学python使用的就是python3.8,在安装各种库的时候,总会有各种报错,真的有点让人奔溃。Anaconda在安装过程中就会安装一些常用的库,其次,当我们想要安装其他库时也很方便。当然大家也可以选择安装其他的一些软件,2.2 scrapy使用流程这里默认大家已经安装好scrapy库,大家要记得要在命令行里输入以下命令啊。
暂无评论
爬取Cnblogs首页文章,爬取的内容包括:标题 、推荐数 、链接、内容预览、作者、作者blogs链接、评论数、查看数。
这篇博文详细解析了Python爬虫中常用的requests库,包含了使用方法和注意事项,适合初学者学习和实践。内容由两万字组成,详解了requests库的各种功能和用法,帮助读者深入理解该库的原理和实
一 、增量式爬虫什么时候使用增量式爬虫:二 、增量式爬虫概念:如何进行增量式爬取工作:三、示例爬虫文件管道文件
基于实际的工作需要,写了个简单例子,供参考,如果有疑问的可以留言
Python爬虫从入门到高级实战教程,包含了Requests库、Beautiful Soup库、Scrapy框架、Selenium与PhantomJS的使用、数据存储与处理等内容,并提供了多个爬取实战
1.在Scrapy工程下新建“middlewares.py” # Importing base64 library because we'll need it ONLY in case if the
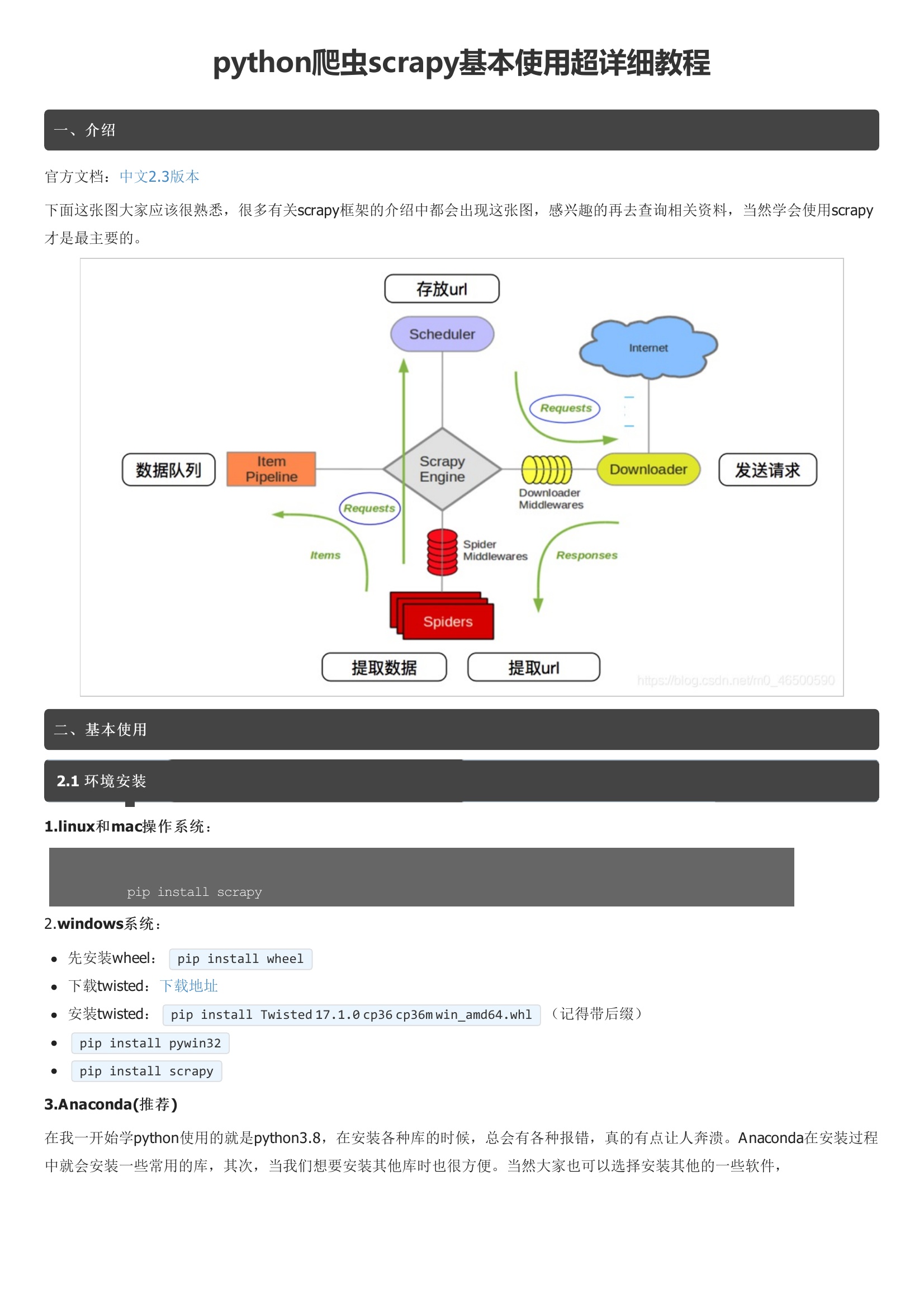
Scrapy是当今世界上最为强大的Python爬虫框架之一,通过Scrapy,开发者可以快速构建高效实用的爬虫,本章将带领大家学习使用Scrapy爬虫框架,编写属于自己的第一个网络爬虫。
Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
基于python3.6的微博爬虫(scrapy)
我参考了多个scrapy教程,各有特点,我综合到一起,再加上自己的一些理解,怕以后自己忘了,整理个文档,分享给需要的人。


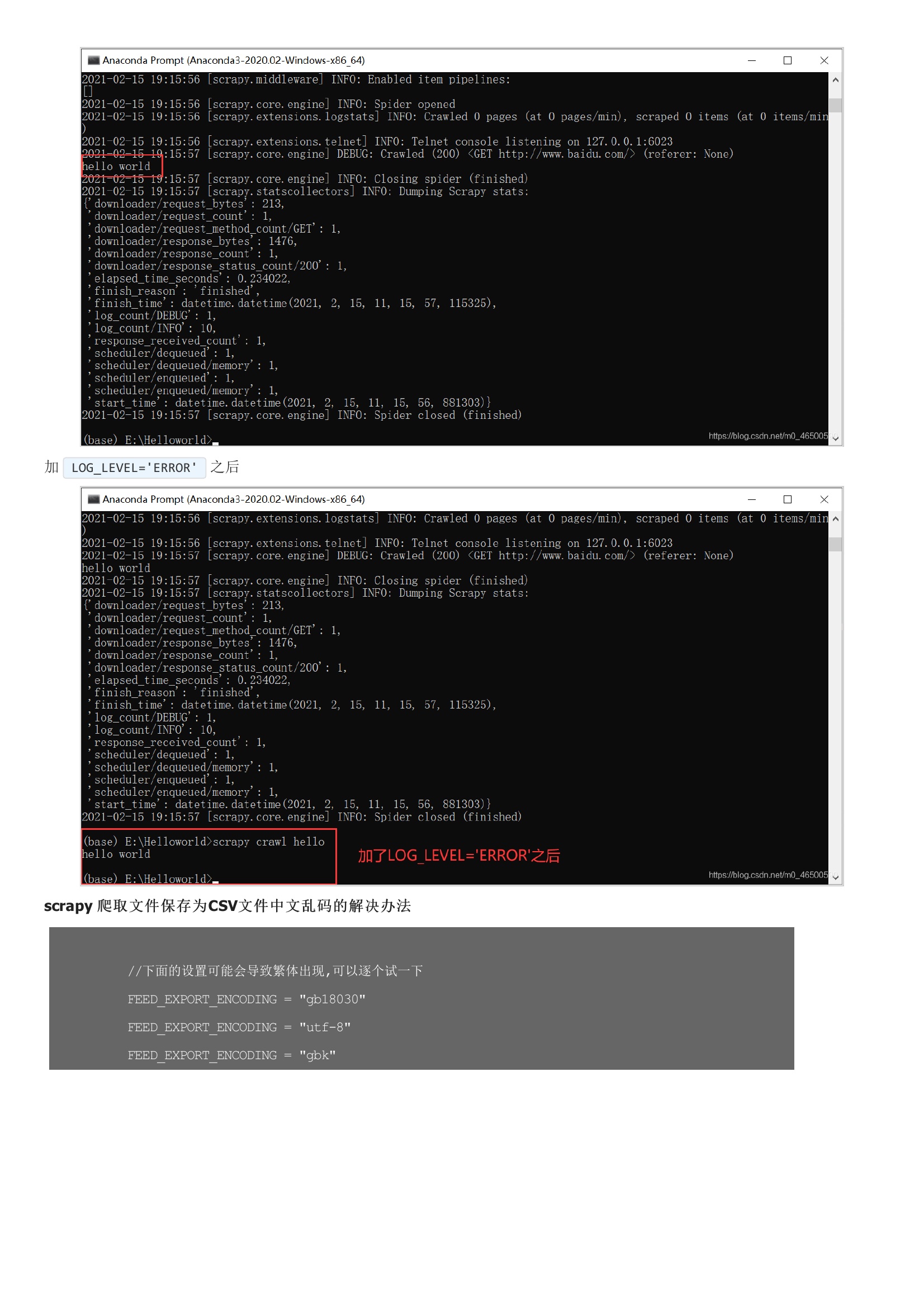
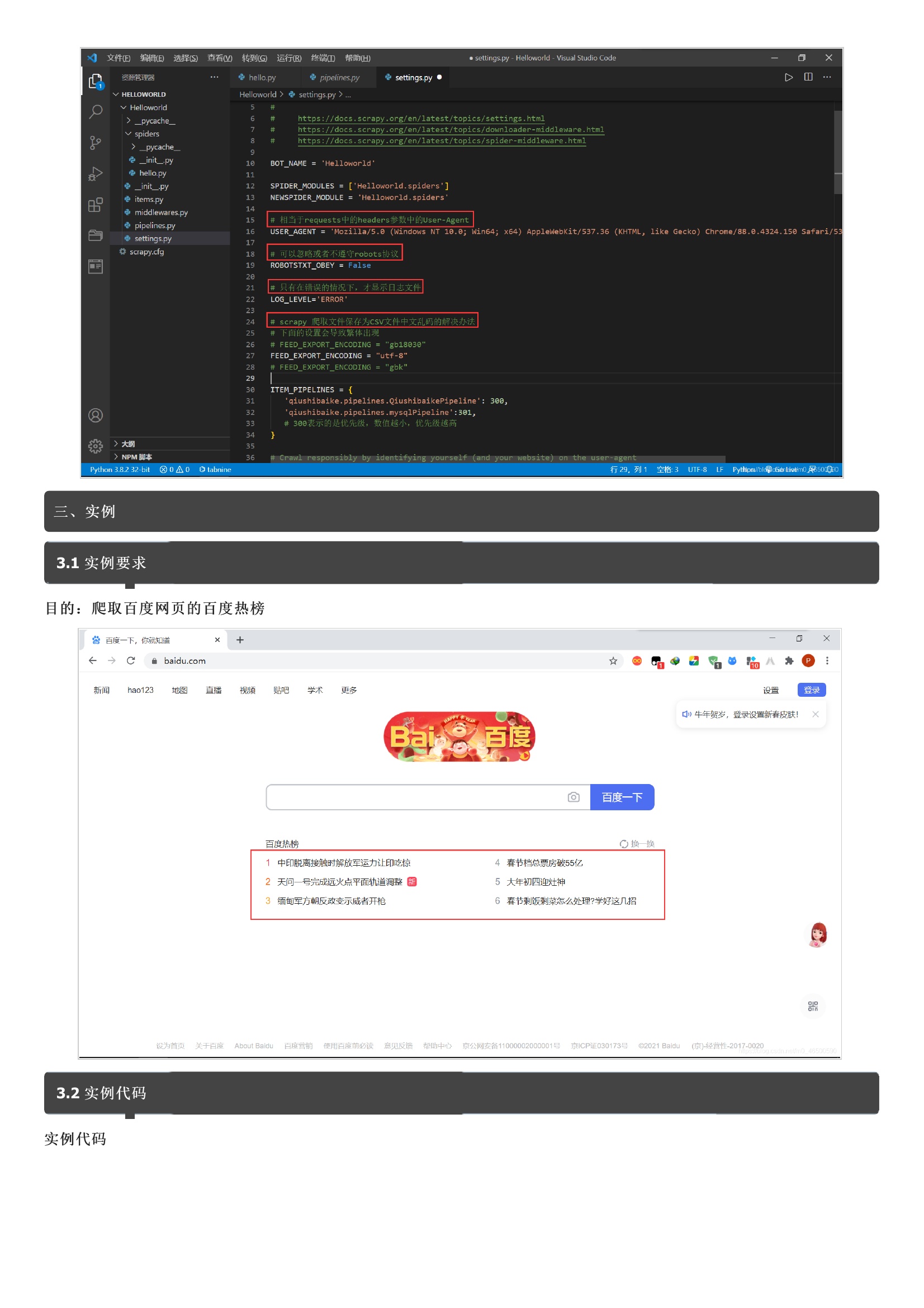
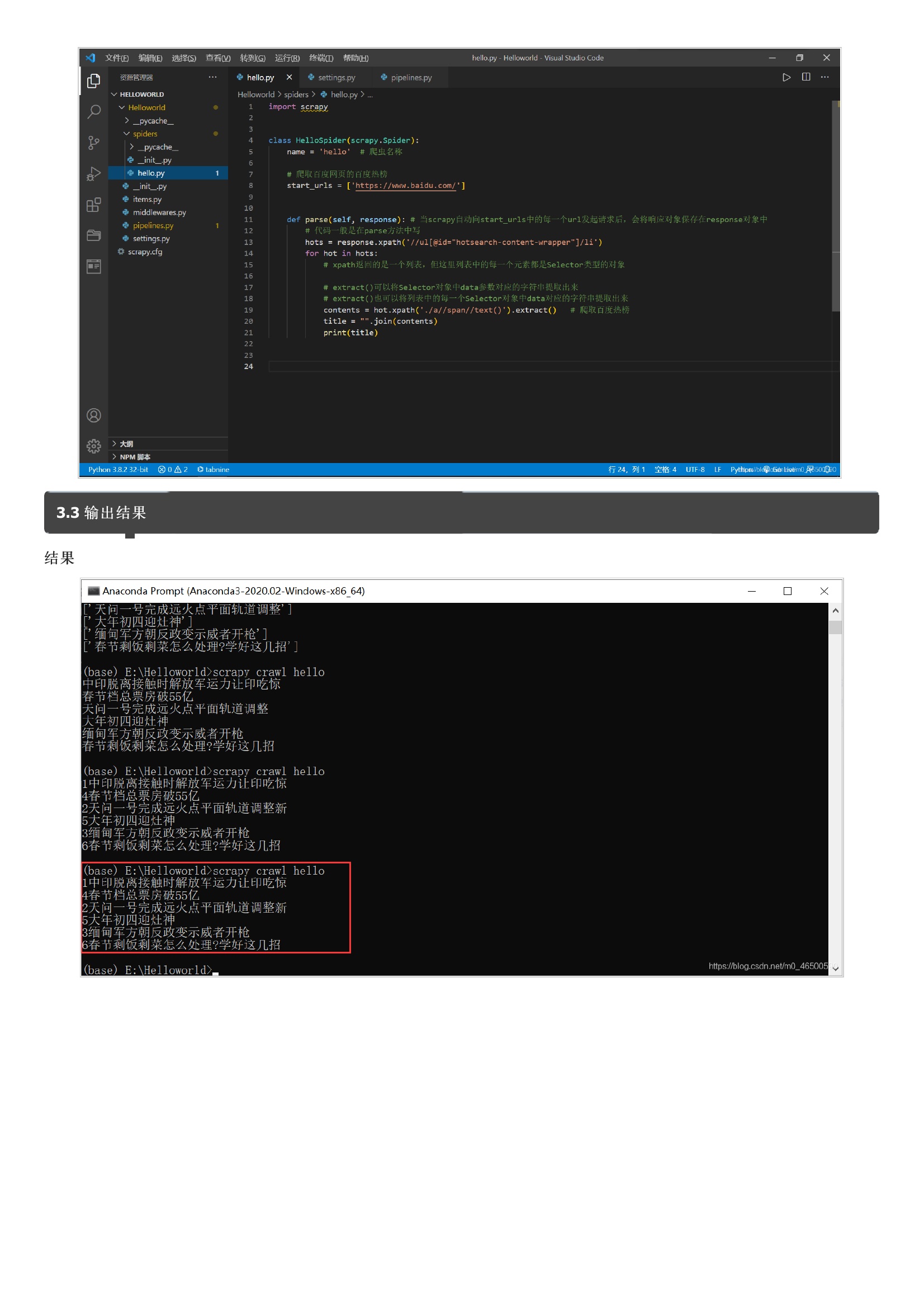
暂无评论