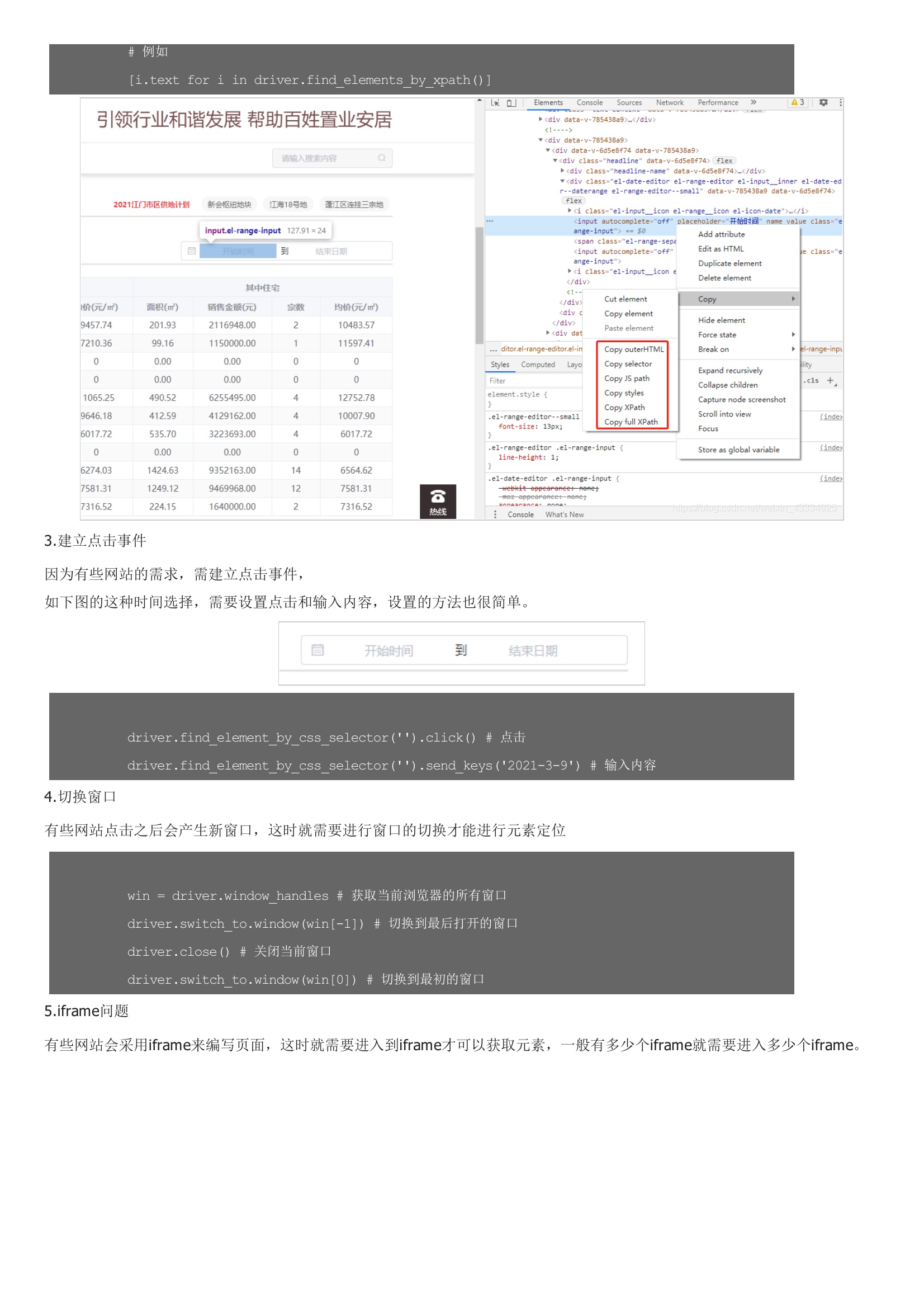
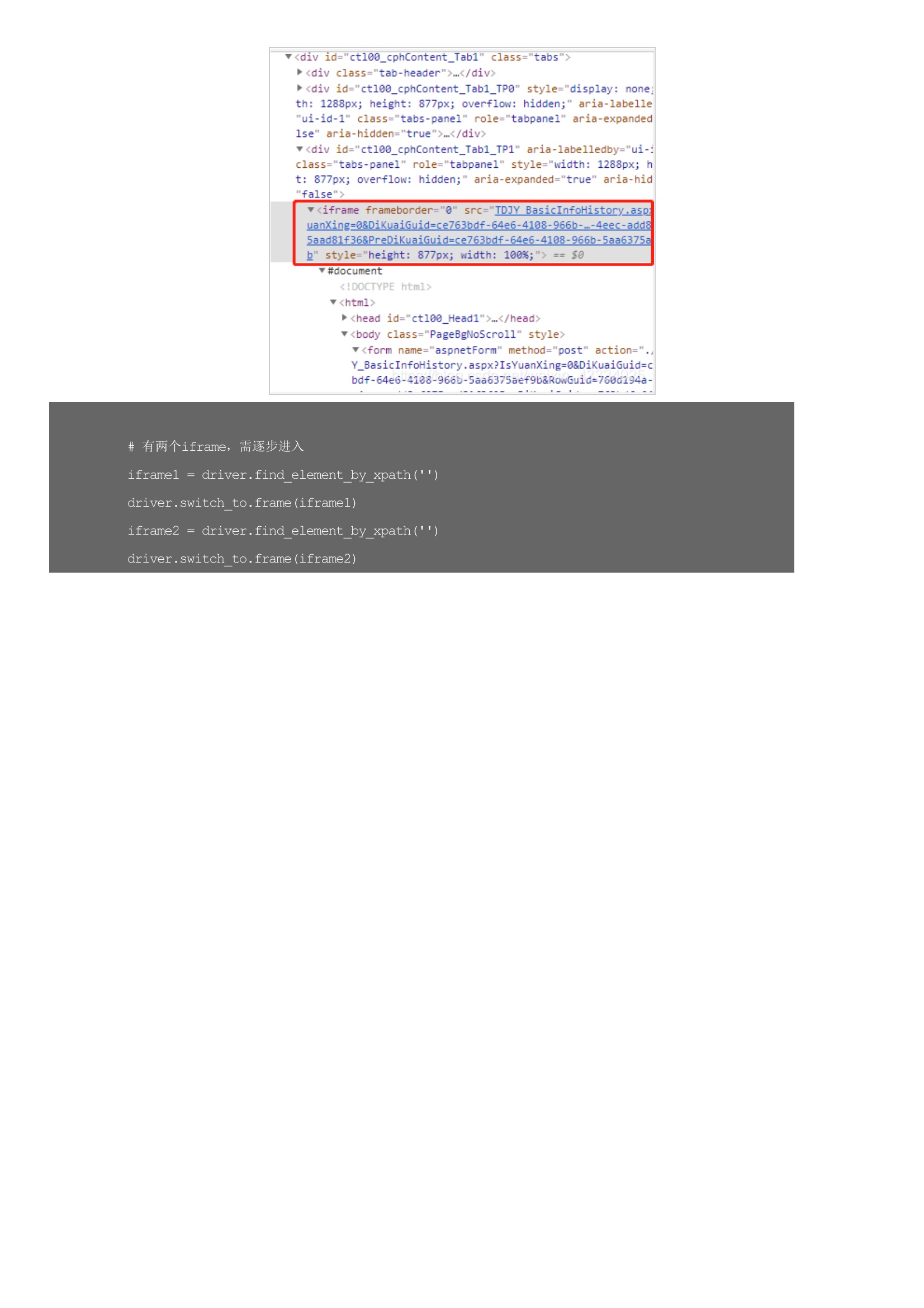
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器。
暂无评论
Python爬虫数据的分类及json数据使用小结
主要介绍了Python selenium实现断言3种方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
主要介绍了python保存文件方法小结,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下
提高性能有如下方法 1、Cython,用于合并python和c语言静态编译泛型 2、IPython.parallel,用于在本地或者集群上并行执行代码 3、numexpr,用于快速数值运算 4、mul
爬取网页上的信息import time from selenium import webdriver path C Program Files Google Chrome Applic
以世纪佳缘网为例,思考自己所需要的数据资源,并以此为基础设计自己的爬虫程序。应用python伪装成浏览器自动登陆世纪佳缘网,加入变量打开多个网页。通过python的urllib2函数进行世纪佳缘网源代
DHTCrawlerpython编写的DHTCrawler网络爬虫,抓取DHT网络的磁力链接。文件collector.pydht网络爬虫脚本抓取dht网络的磁力链接,使用libtorrent的pyth
由Python编写的网络爬虫工具,可以自动抓取网页内容并进行数据分析和处理。该工具不仅具有高效快捷的爬取速度,还能够进行数据可视化和导出等操作,是一款功能齐全的网络爬虫工具。使用该工具需要一定的Pyt
1基于Python的网络爬虫 网络爬虫又称网络蜘蛛,或网络机器人。网络爬虫通过网页的 链接地址来查找网页内容,并直接返回给用户所需要的数据,不需 要人工操纵浏览器获取。脚daon是一个广泛使用的脚本语
基于 Python 的专用网络爬虫的设计与实现在很多用户使用搜索引擎的时候,往往会出现很多不必要的信息,这就是传统搜索引擎的局限性。在通过传统的搜索引擎进行信息搜索时,也要求用户对搜索到的信息进行分析

暂无评论