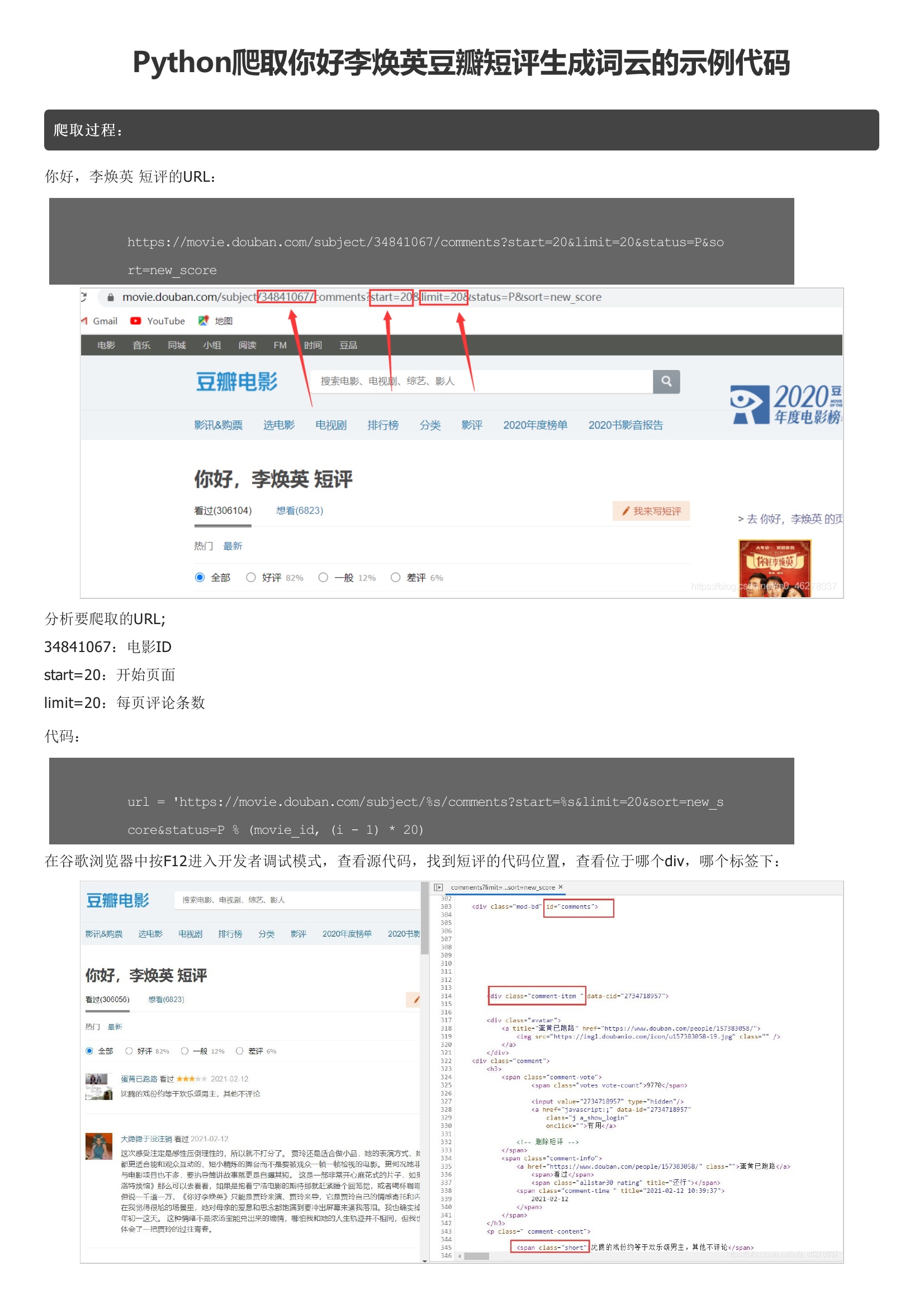
爬取过程:你好,李焕英 短评的URL:分析要爬取的URL;代码:在谷歌浏览器中按F12进入开发者调试模式,查看源代码,找到短评的代码位置,查看位于哪个div,哪个标签下:可以看到评论在div[id=‘comments']下的div[class=‘comment-item']中的第一个span[class=‘short']中,使用正则表达式提取短评内容,即代码为:背景图:生成的词云:完整代码:WordCloud各含义参数如下:
暂无评论
主要介绍了Python实现的爬取小说爬虫功能,结合实例形式分析了Python爬取顶点小说站上的小说爬虫功能相关实现技巧,需要的朋友可以参考下
python 爬取免费简历模板网站的示例
将 pyd 文件下载到本地,新建项目,把 pyd 文件放进去项目根目录下新建 runner.py,写入以下代码即可运行并抓取示例代码百度新闻
python 多线程爬取壁纸网站的示例
Python开发爬取豆瓣图书信息,并保存到本地,已经过测试,欢迎交流!
1.发送请求:requests 2.获取相应数据:对方及其直接返回 3.解析并提取想要的数据:re 4.保存提取后的数据:with open()文件处理 1.发送请求
在本篇文章里小编给大家整理的是关于python爬取网易云音乐热歌榜实例代码,需要的朋友们可以学习下。
今天小编就为大家分享一篇关于Python爬取数据保存为Json格式的代码示例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
python贝壳房源爬取,价格爬取
主要介绍了Python爬虫爬取、解析数据操作,结合实例形式分析了Python爬虫爬取、解析、存储数据相关操作技巧与注意事项,需要的朋友可以参考下




暂无评论