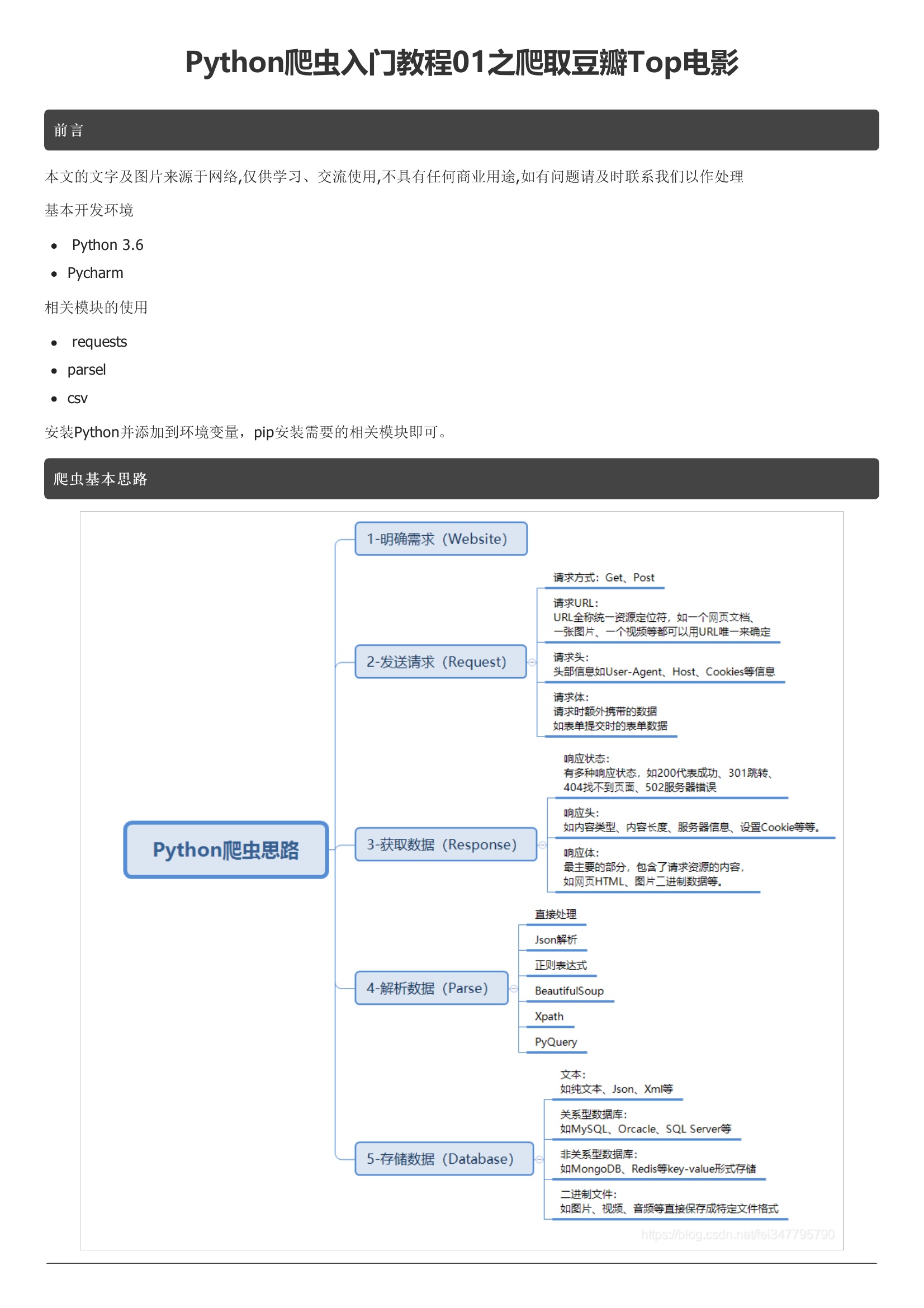
Python爬虫入门教程01之爬取豆瓣Top电影
暂无评论
# -*-coding:utf-8-*- import urllib.request from bs4 import BeautifulSoup def getHtml(url): "&qu
主要介绍了Python使用mongodb保存爬取豆瓣电影的数据过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
我们的需求是利用python爬虫爬取豆瓣电影排行榜数据,并将数据通过pandas保存到Excel文件当中(步骤详细) 我们用到的第三方库如下所示: import requests import pan
批量下载豆瓣电影TOP250(测试可以爬)资源环境python3模块支持bs4requestspymysqlmysql本地数据库/远程也可
爬取指定标签List下评分8.5分以上的图书信息,包括书名、作者、评分、简介,并保存到excel,以标签分类,放到不同的sheet中。核心代码: title= book.find_element_by
豆瓣网电影人名数据爬取,得到的是全网段的数据
主要介绍了Java爬取豆瓣电影数据的方法,结合实例形式详细分析了Java爬取豆瓣电影数据相关原理、操作步骤、实现技巧与注意事项,需要的朋友可以参考下
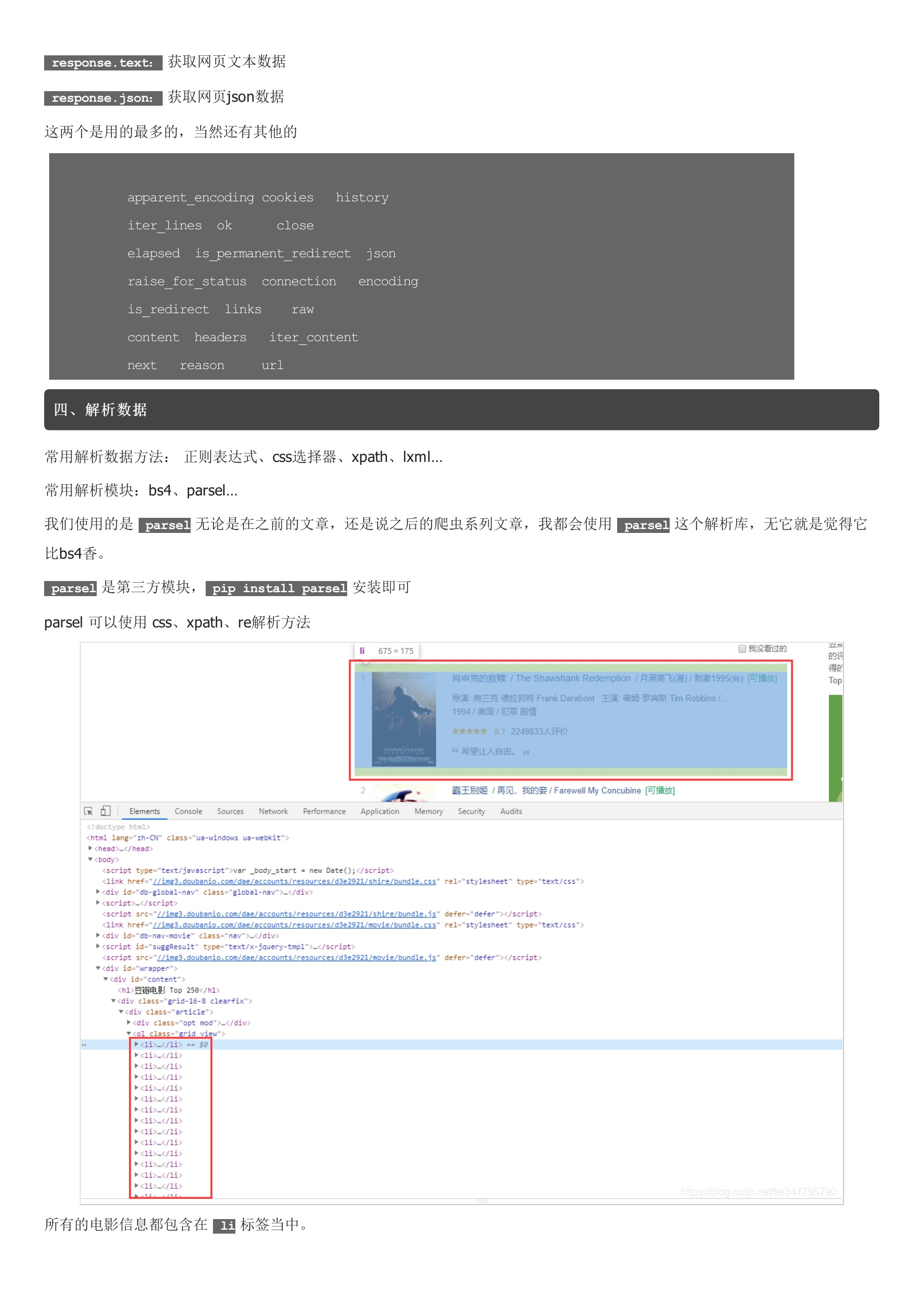
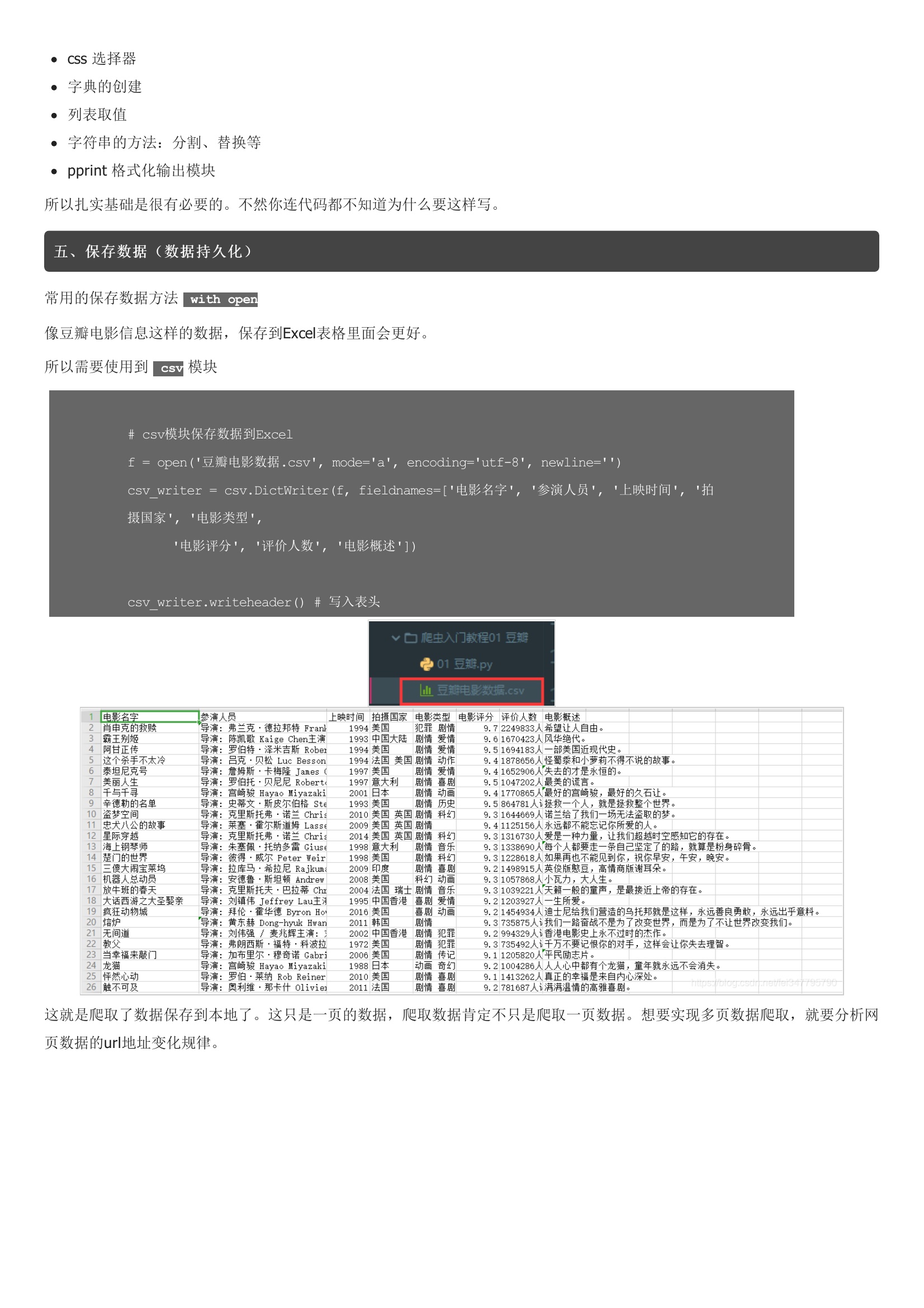
豆瓣电影网站https://movie.douban.com/top250 列出了评分比较高的250部电影的简 介,进入该网可以看到这些电影的信息,由于电影比较多,一个页面只列出 25部电影,全部电影
使用Xpath语法爬取豆瓣读书Top250(csv存取数据) 使用的软件是Spyder 网页地址:https://book.douban.com/top250?start=0 直接上代码: 建议大家从
爬取豆瓣读书某一列的标签,存储为CSV格式,为了不被系统封IP,用了点小技巧






暂无评论