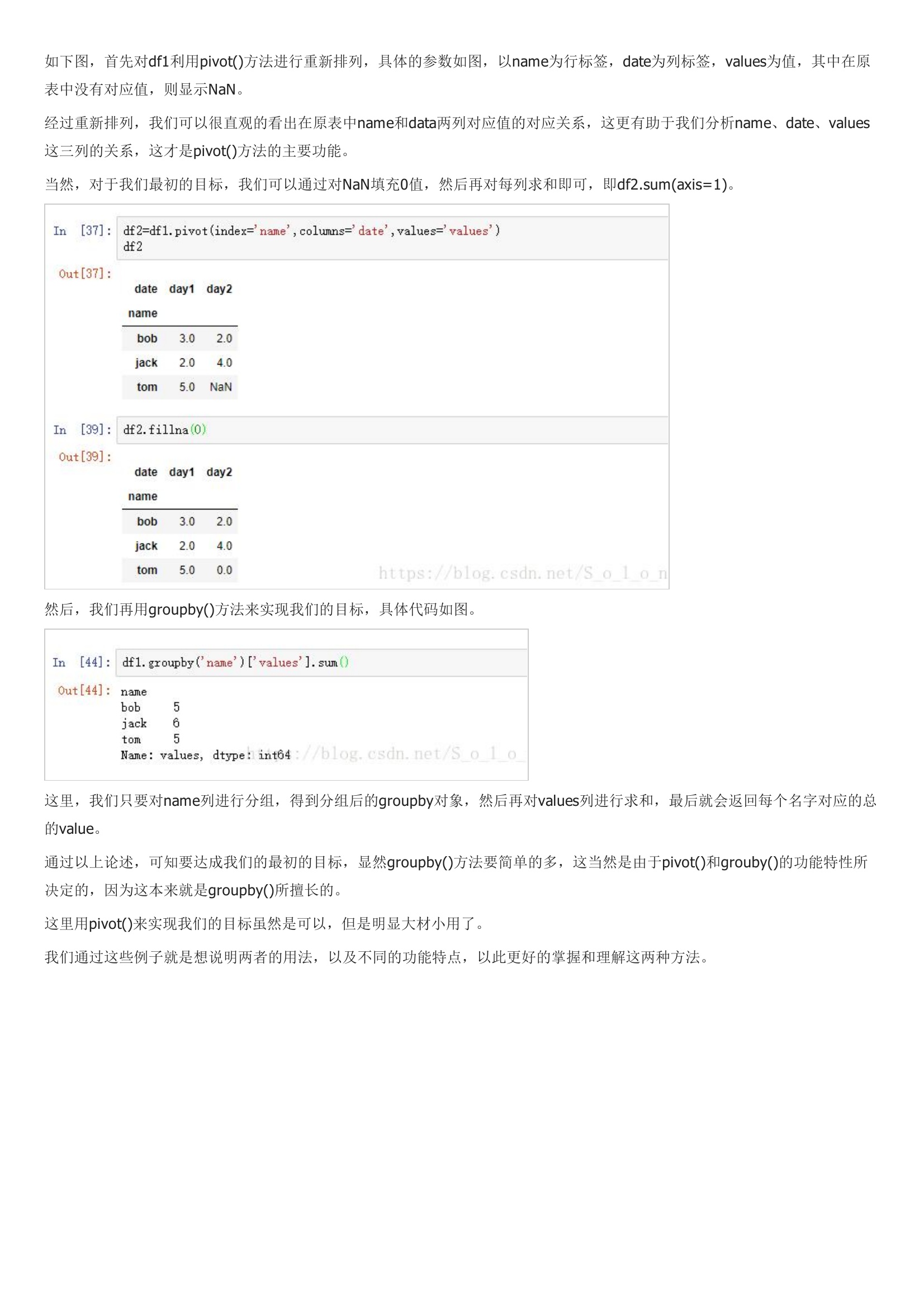
如下图,首先对df1利用pivot()方法进行重新排列,具体的参数如图,以name为行标签,date为列标签,values为值,其中在原表中没有对应值,则显示NaN。然后,我们再用groupby()方法来实现我们的目标,具体代码如图。这里,我们只要对name列进行分组,得到分组后的groupby对象,然后再对values列进行求和,最后就会返回每个名字对应的总的value。通过以上论述,可知要达成我们的最初的目标,显然groupby()方法要简单的多,这当然是由于pivot()和grouby()的功能特性所决定的,因为这本来就是groupby()所擅长的。这里用pivot()来实现我们的目标虽然是可以,但是明显大材小用了。


暂无评论