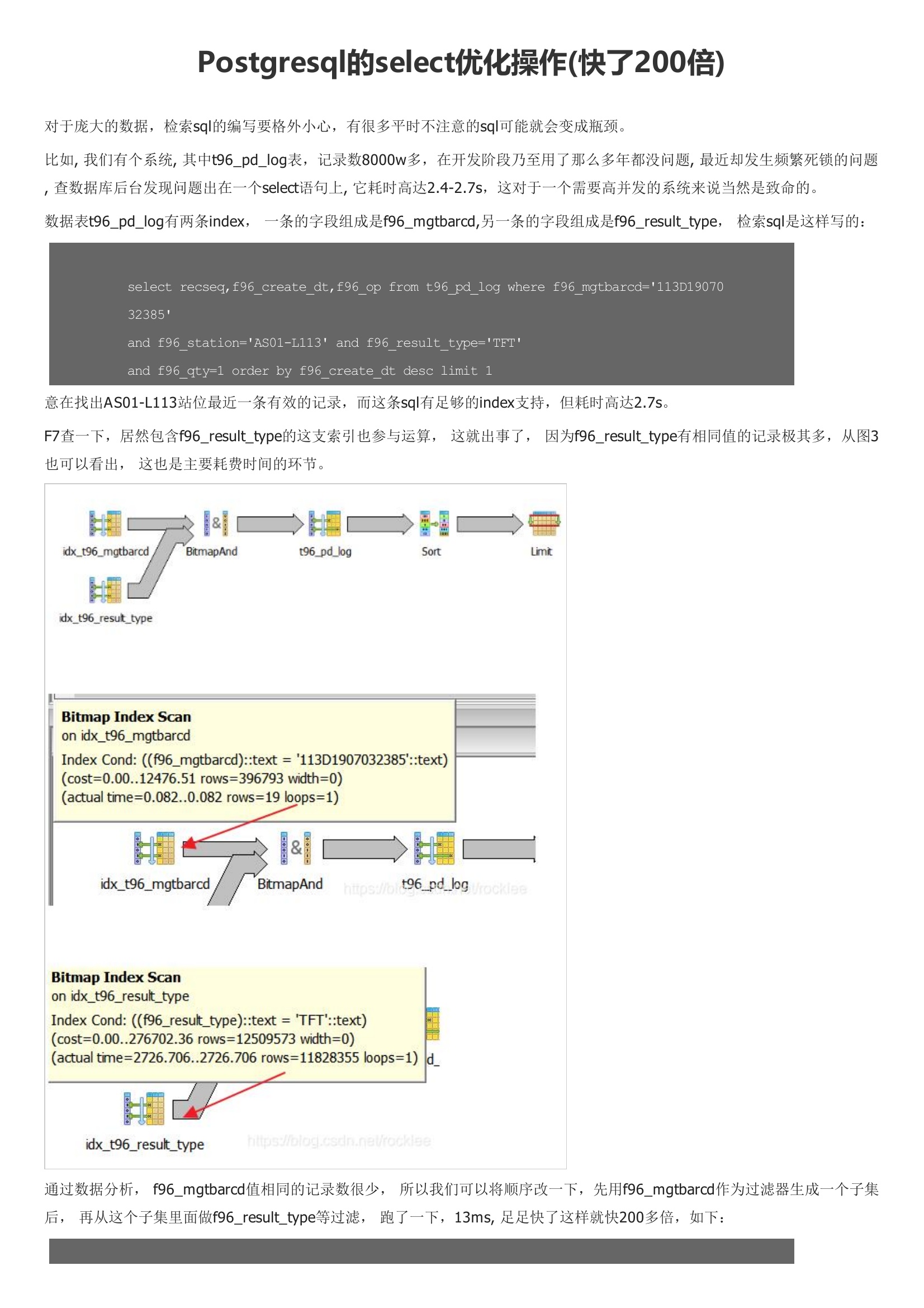
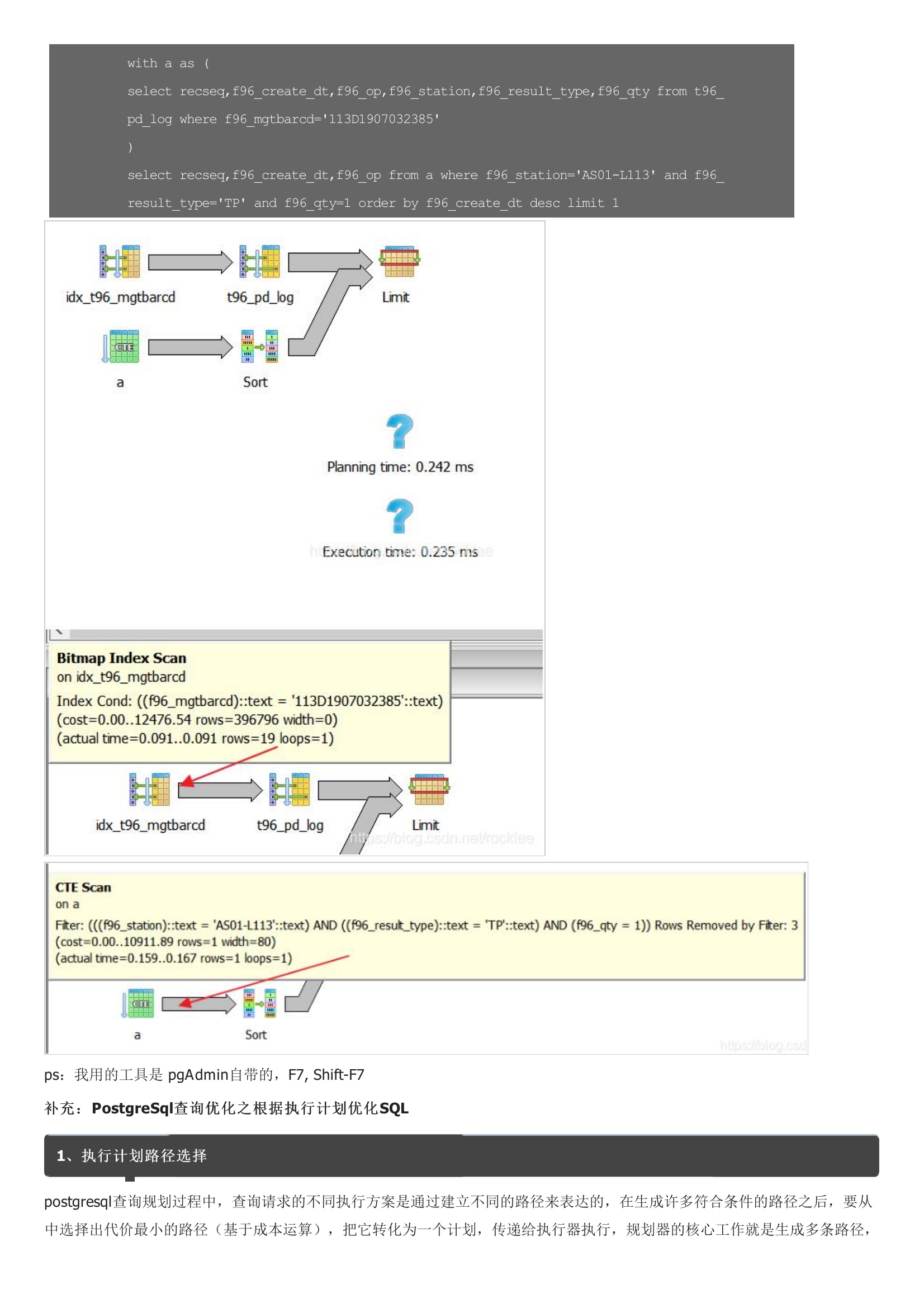
对于庞大的数据,检索sql的编写要格外小心,有很多平时不注意的sql可能就会变成瓶颈。数据表t96_pd_log有两条index, 一条的字段组成是f96_mgtbarcd,另一条的字段组成是f96_result_type, 检索sql是这样写的:意在找出AS01-L113站位最近一条有效的记录,而这条sql有足够的index支持,但耗时高达2.7s。这些信息保存在pg_class表的reltuples和relpages列中。在表较小的情况下,全表扫描比索引扫描更有效, index scan 至少要发生两次I/O,一次是读取索引块,一次是读取数据块。修改后sql:再次查看执行计划:这一次可以看出,ajdbxx和zbajxx表做了hash semi join 消除了nestedloop,cost降到了3231.97。并且使用上了i_t_zhld_ajdbxx_m6子查询中in的结果集有一万多条数据。









暂无评论