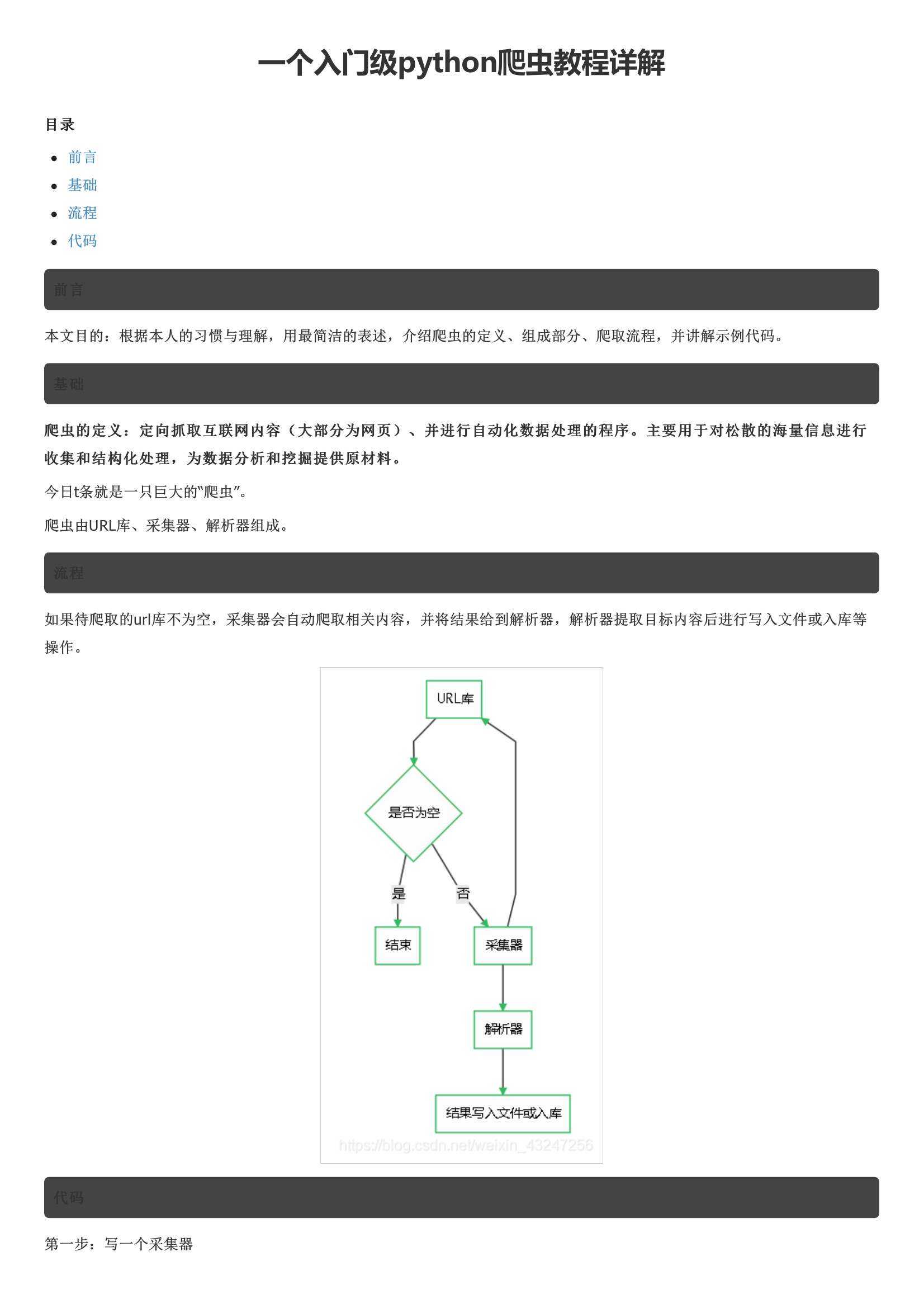
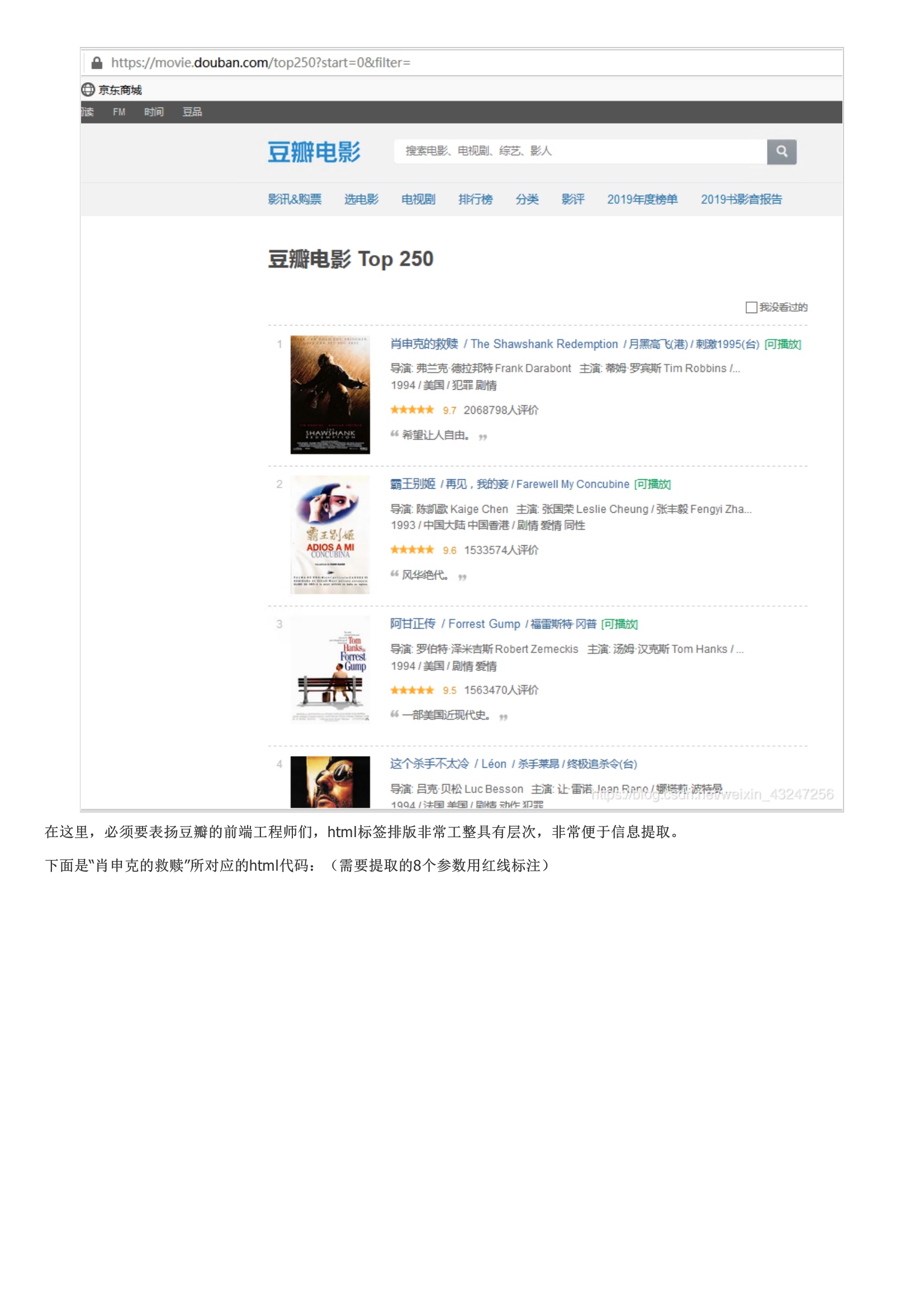
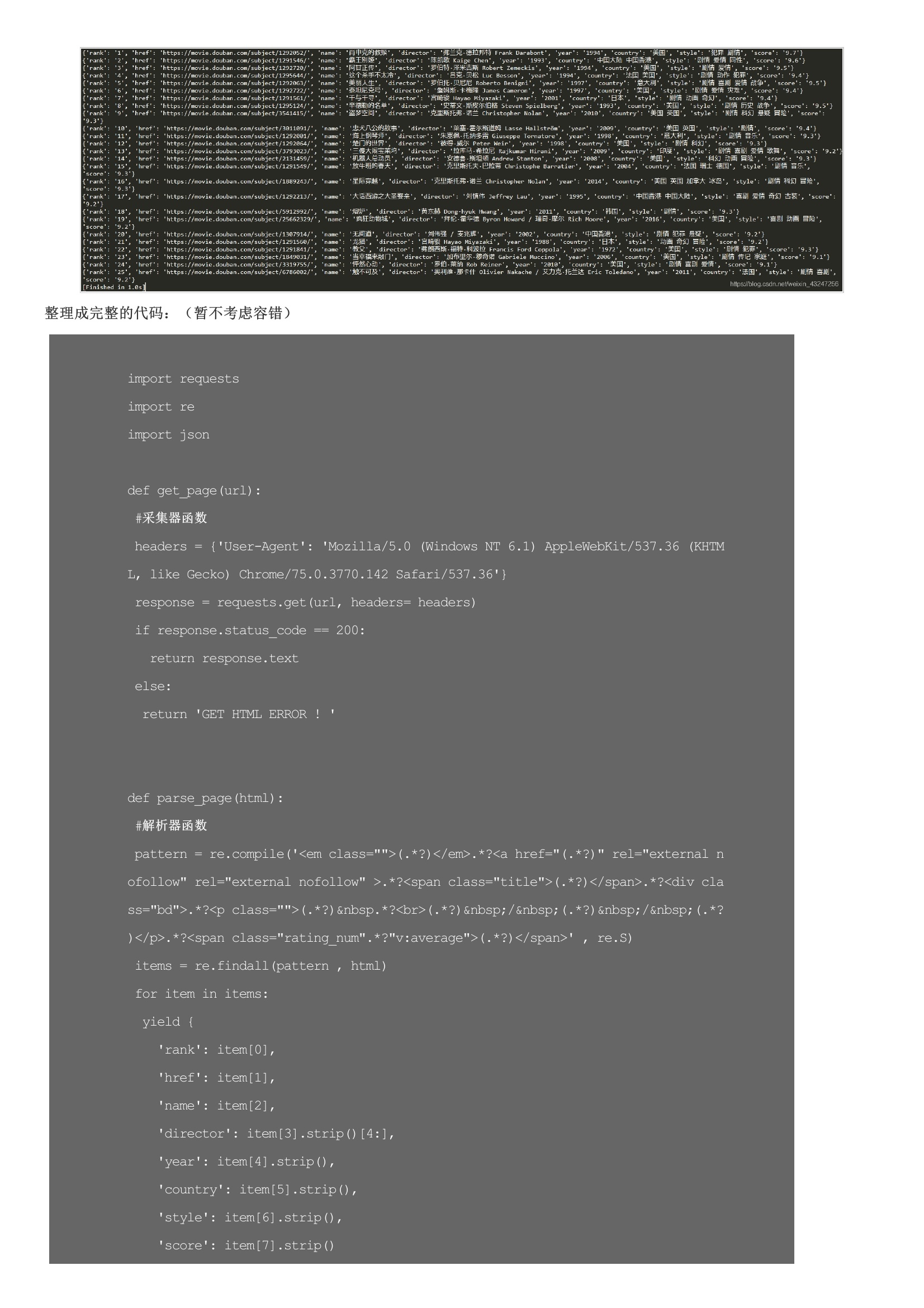
基础今日t条就是一只巨大的“爬虫”。爬虫由URL库、采集器、解析器组成。流程如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作。如果响应代码不是200 ok,说明页面不能正常访问,将函数返回值设置为特殊字符串或代码。整理成字典并写入文本文件。在这里,必须要表扬豆瓣的前端工程师们,html标签排版非常工整具有层次,非常便于信息提取。该函数返回值是一个可迭代的序列。
暂无评论
Hadoop入门级视频教程 后面为描述筹字数为描述筹字数
入门级手机qq美化教程,教没用过ps的童鞋修改手机QQ
pycharm详细教程.pdf入门级
本资料包含有iOS开发的相关文档。多为入门级学习资料,适合新手学习
这是全套的c语言教程,是我学习用
《Python那些事——NLP入门级教程,值得你拥有!.pdf》
Python零基础入门级教程-发布版.pptx,适合所有想学习Python 编程语言的爱好者
Python crawler getting started tutorial
以通俗易懂的语言,结合实例,一问一答,详细的讲诉了SEO的原理及知识点。适合初学者阅读。
Hive入门级编程实例详解。涵盖了各类基础函数使用要点以及Java编写Hive函数等。



暂无评论