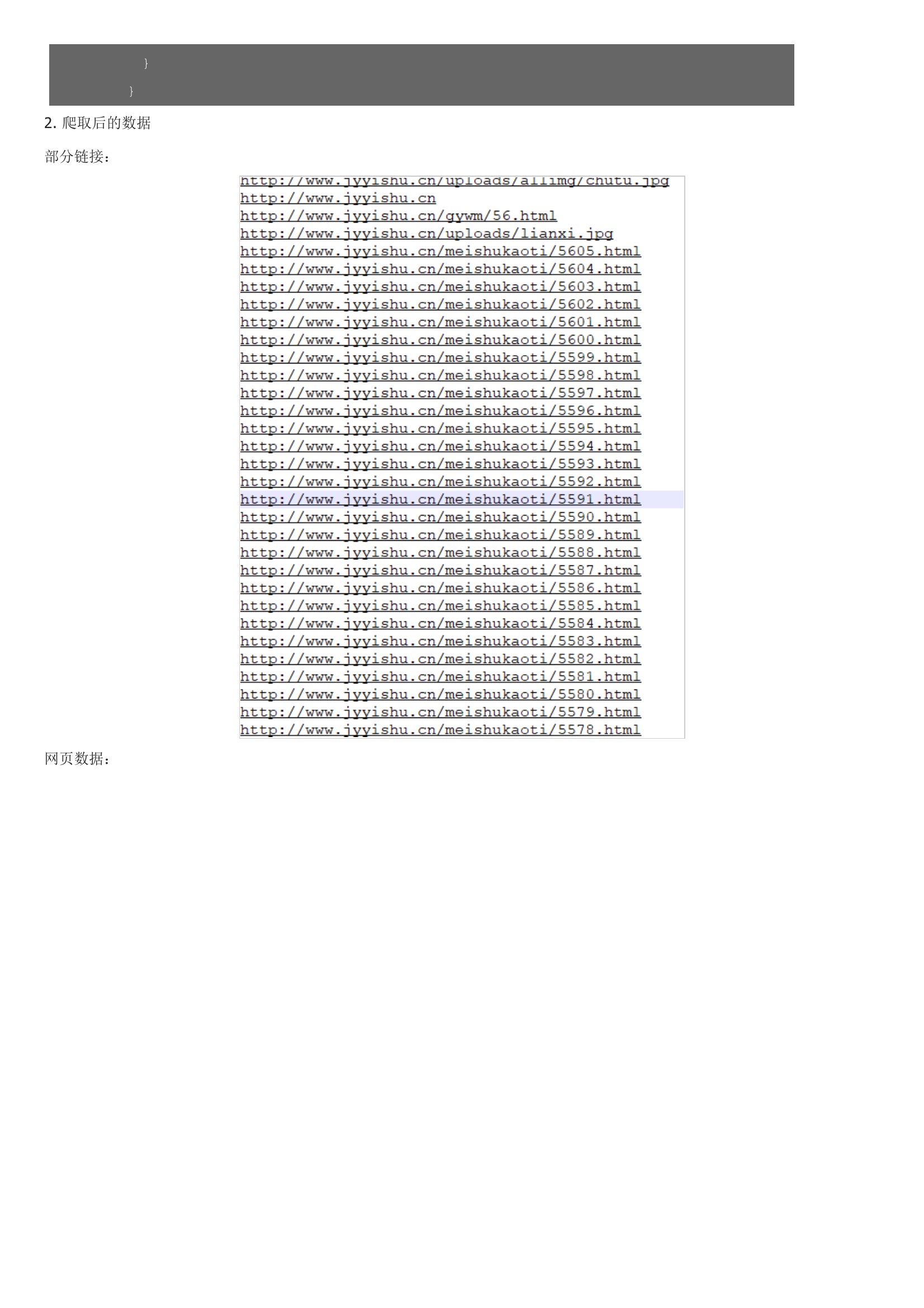
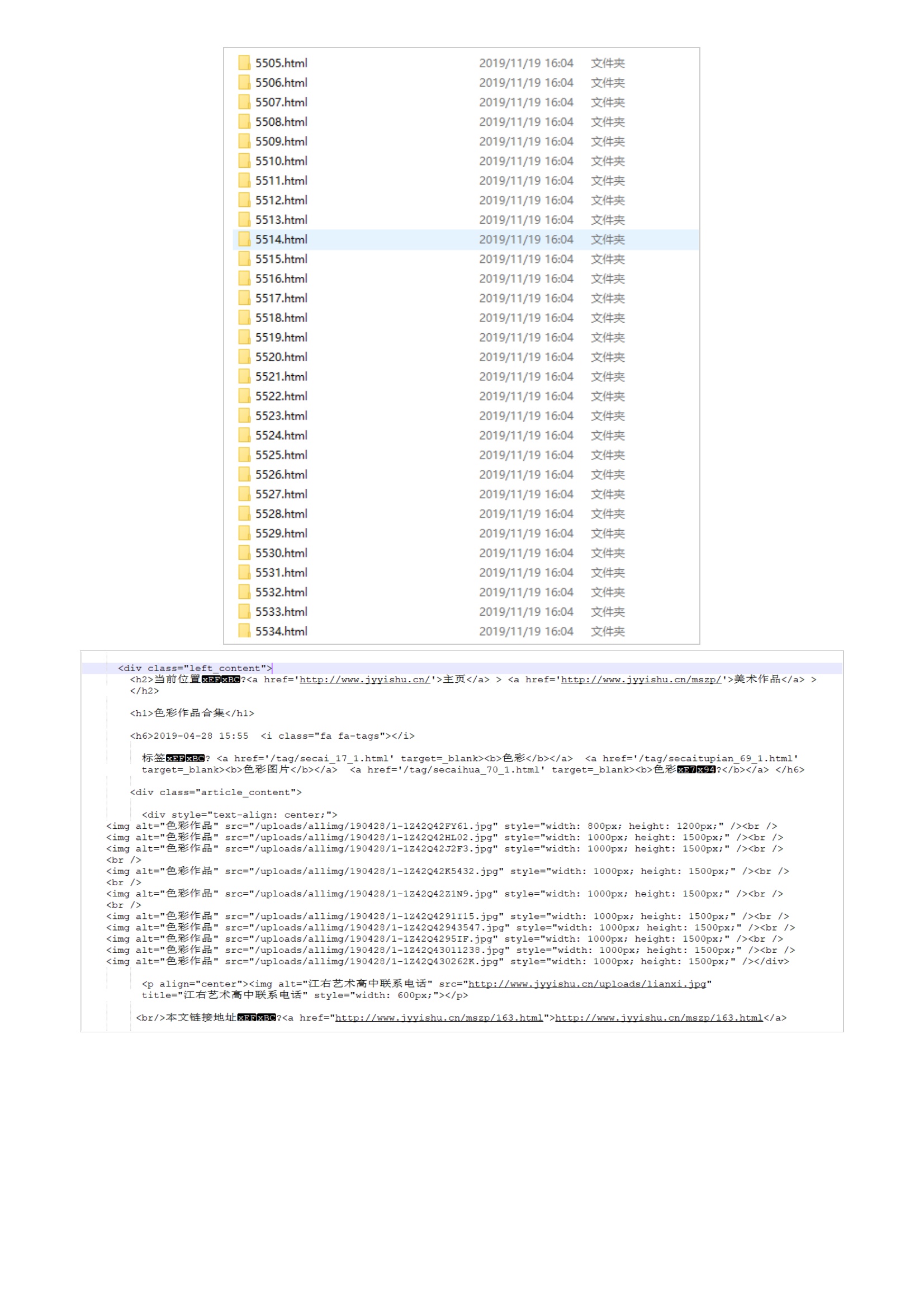
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。所以主要使用递归遍历完成对每个网页内链接的获取和源码的获取,然后剔除重复链接数据爬取后主要使用txt文件储存,根据网址的路径生成想应文件路径2.代码2. 爬取后的数据部分链接:网页数据:
暂无评论
抓取“xmly”鬼故事音频 import json # 在这个url,音频链接为JSON动态生成,所以用到了json模块 import requests headers = { User-Agent:
多个关键字请用空格分隔源代码源代码源代码源代码
很好的团购网站源码学习非常的值得参考简易实现轻松团购每一天
团购网网站JAVA源代码,非常好用全面,是建设和学习团购网站的好资源!
《第一个爬虫项目-爬取唯美小姐姐网站》配套源代码文件,免费下载,供python学习者交流之用,以及爬虫爱好者交流学习之用。
java 爬虫 爬取图片
利用HTML工具,多线程,消息队列,模拟浏览器实现爬取网页数据
在eclispe下写的爬取200个单词的翻译,并行效果较好
java爬取京东数据,利用java的dom类,运用request获取前端页面的dom,再通过特定的格式获取对应的标签。
轻松搞定你的个人网站,世界不出不在你的空间!




暂无评论