这类符号是HTML、XML 等 SGML 类语言的转义序列。它们不是”编码“,也就是说我们不能使用utf-8、gbk等编码进行处理,需要使用HTMLParse进行处理,完整代码如下:此时运行结果如下:那么此时就已经大功告成了!!!
暂无评论
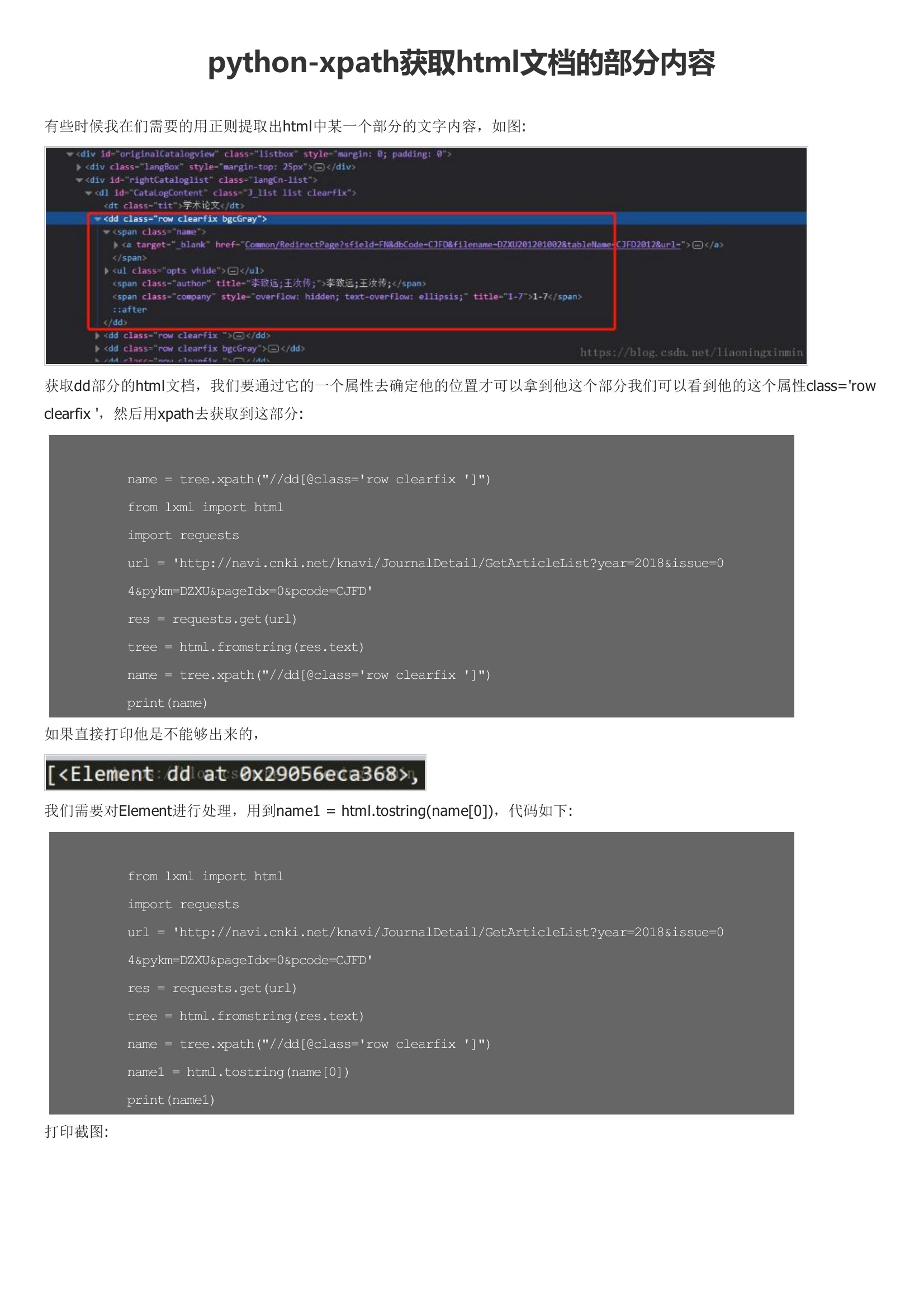
主要介绍了python-xpath获取html文档的部分内容,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
本资料为sliverlight学习的部分内容,非完整版,请诸位看准再下载,包括三章内容。
MYbatis的一对多查询,及登录注册
关于oracle pl/sql的基础支持的了解与诠释非常仔细和认真
这是我学ccna课程时的笔记整理,看着挺清晰的。
MIMO是多入多出系统 。。。。。。
不完整 但还可以看看 了解一下 还有的下次再传
关于Java-redis及其jedis相关学习文档内容,供大家参考使用
新出版的图书,据说还不错,网络流传一部分,分享给大家
比较不错的快递管理系统一部分,仅作为学术交流!

暂无评论