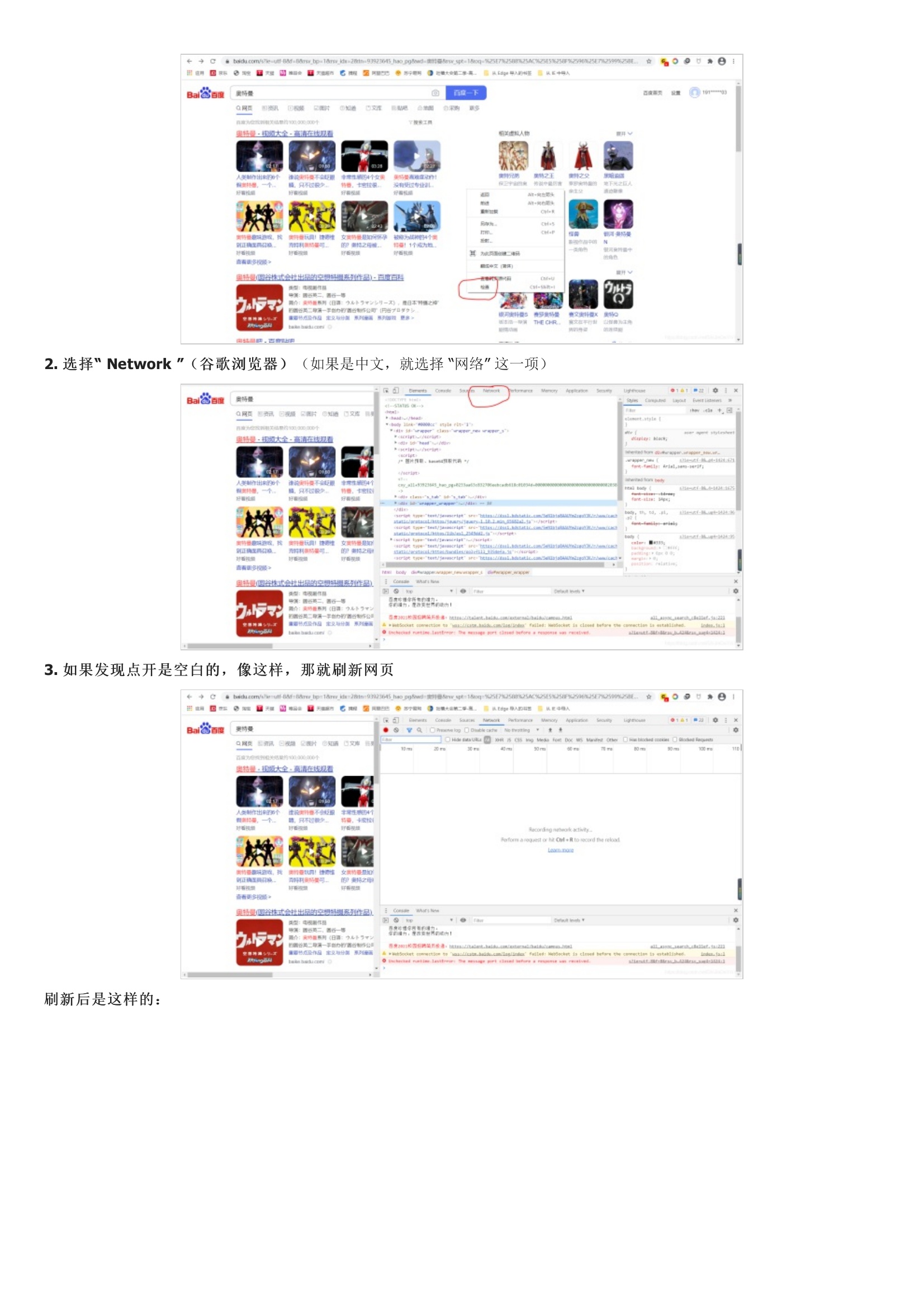
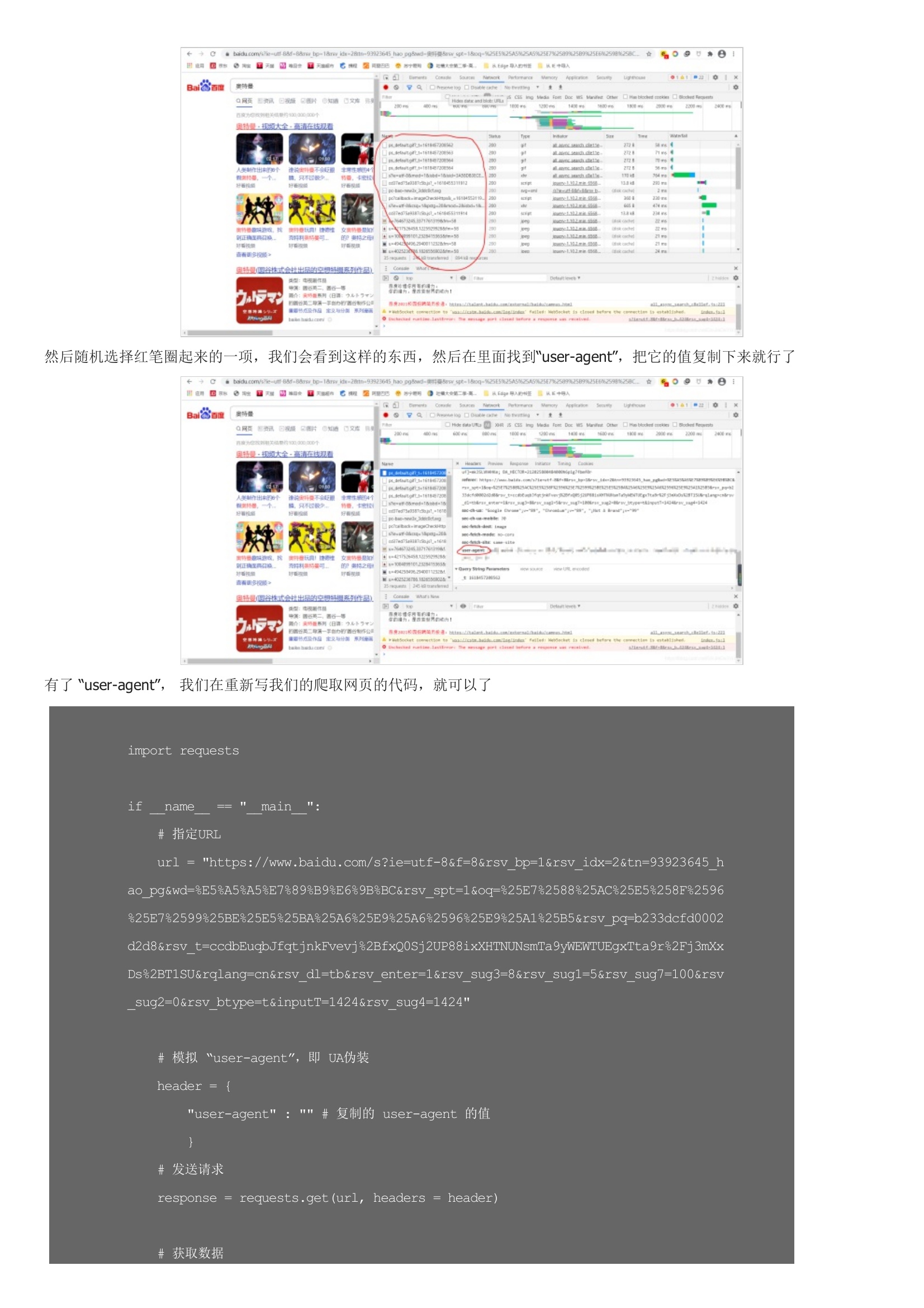
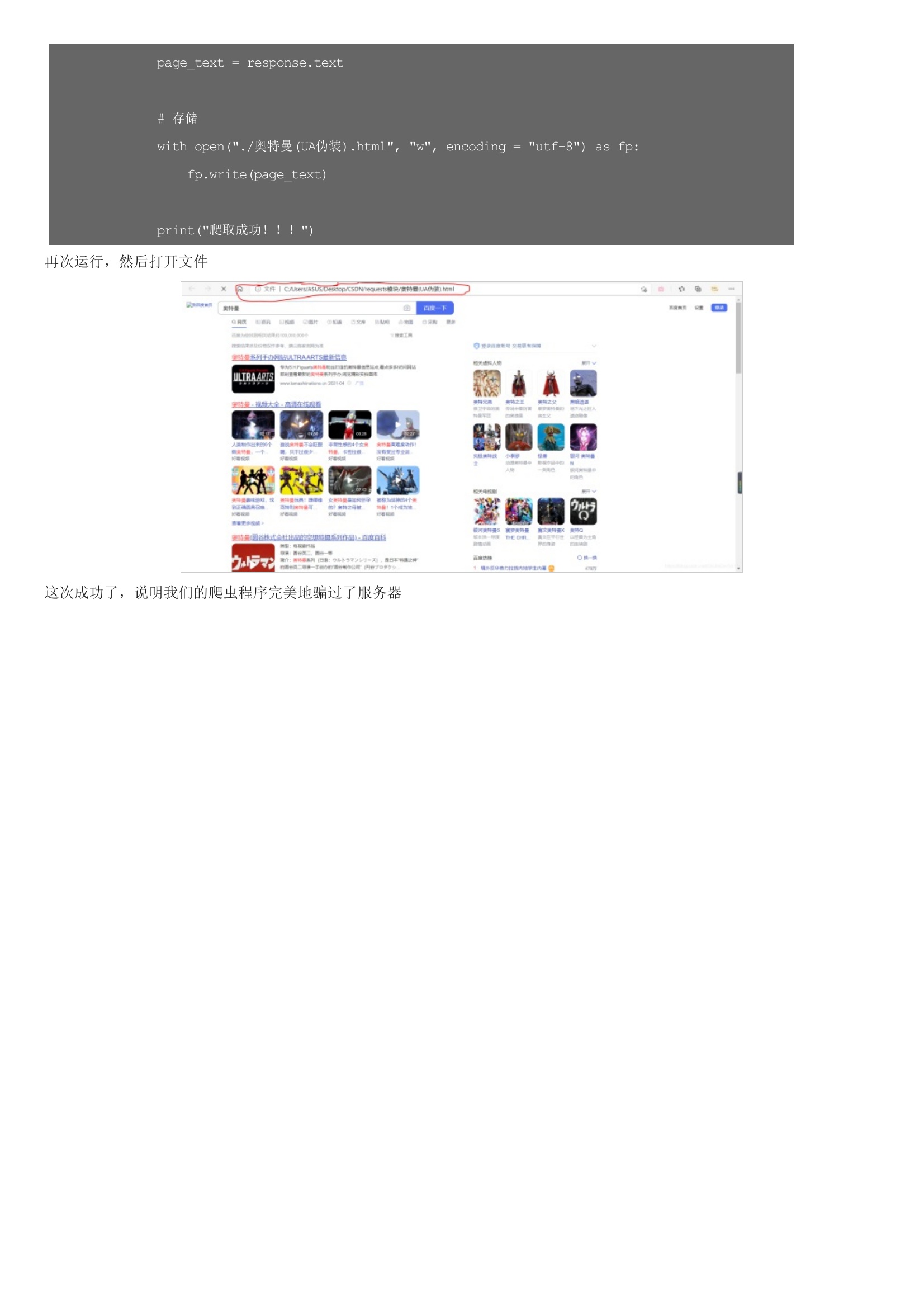
不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度。这句话的意思就是说,搜狗或是百度注意到发送请求的是爬虫程序,而不是人工操作。简单来说,就是程序访问和我们使用浏览器访问是有区别的,被请求的服务器都是靠 user-agent 来判断访问者的身份,如果是浏览器就接受请求,否则就拒绝。既然要识别 user-agent ,那么我们就让爬虫模拟 user-agent 好了。然后随机选择红笔圈起来的一项,我们会看到这样的东西,然后在里面找到“user-agent”,把它的值复制下来就行了有了 “user-agent”, 我们在重新写我们的爬取网页的代码,就可以了再次运行,然后打开文件这次成功了,说明我们的爬虫程序完美地骗过了服务器


暂无评论