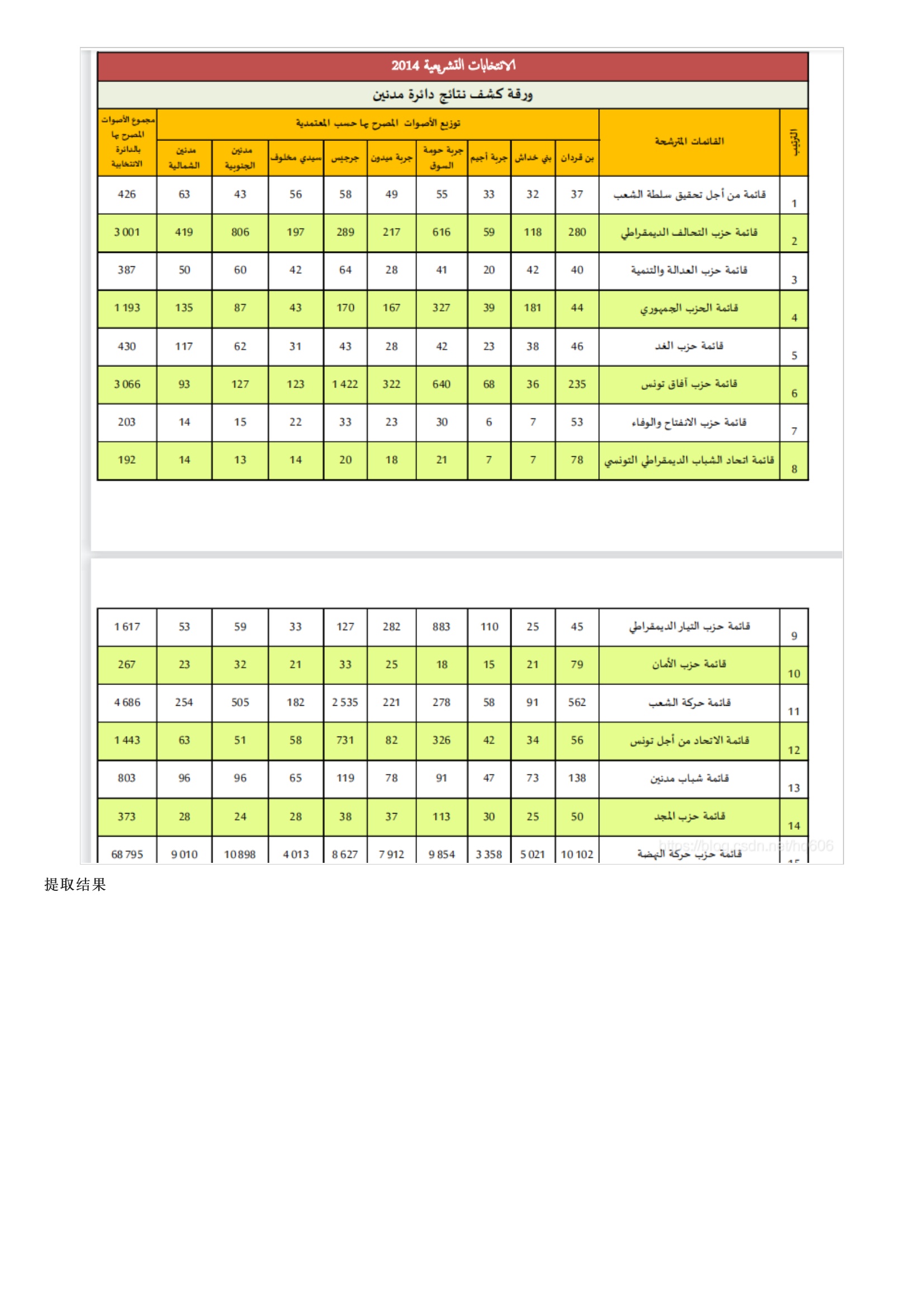
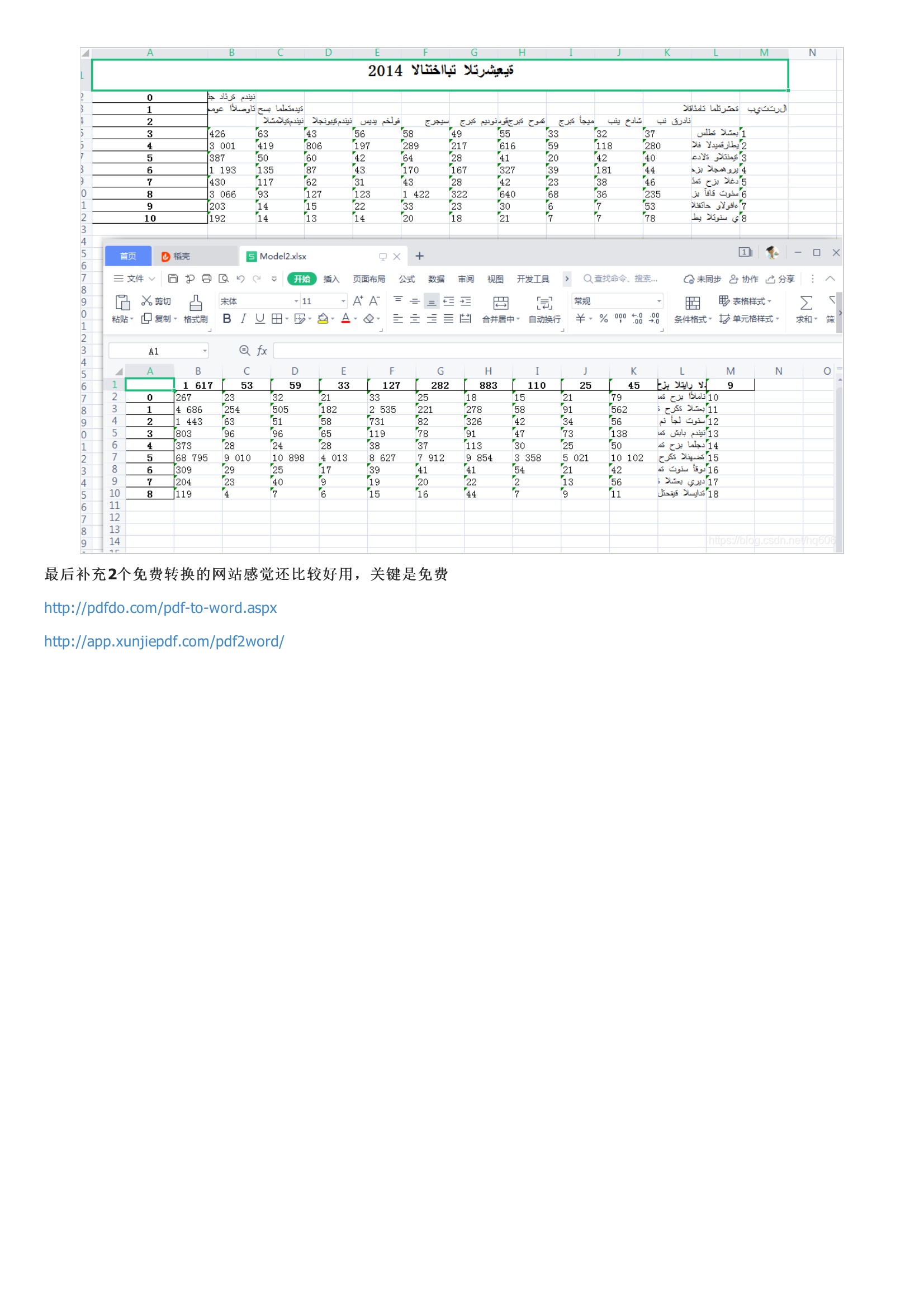
先讲一下为啥要写这个文章,网上其实很多这种PDF转化的代码和软件。我一直想用Python做,但是网上搜到的代码很多都不能用,很多是2.7版本的代码,再就是PDF需要用到的库在导入的时候,很多的报错,解决起来特别费劲,而且自从2021年初以来,似乎网上很少有关PDF转化的代码出现了。我在研究了很多代码和pdfminer的用法后,总结了几个方法,目前这几种方法可以解决大多数格式的转化,后面我也专门放了提取PDF表格的代码,文末有高效的免费在线工具推荐。下面这个是我最最推荐的方法 ,简单高效 ,只要是标准PDF文档,里面的图片和表格都可以保留格式下面是另外三种常用方法以下是pdfplumber测试效果源文件如下





暂无评论