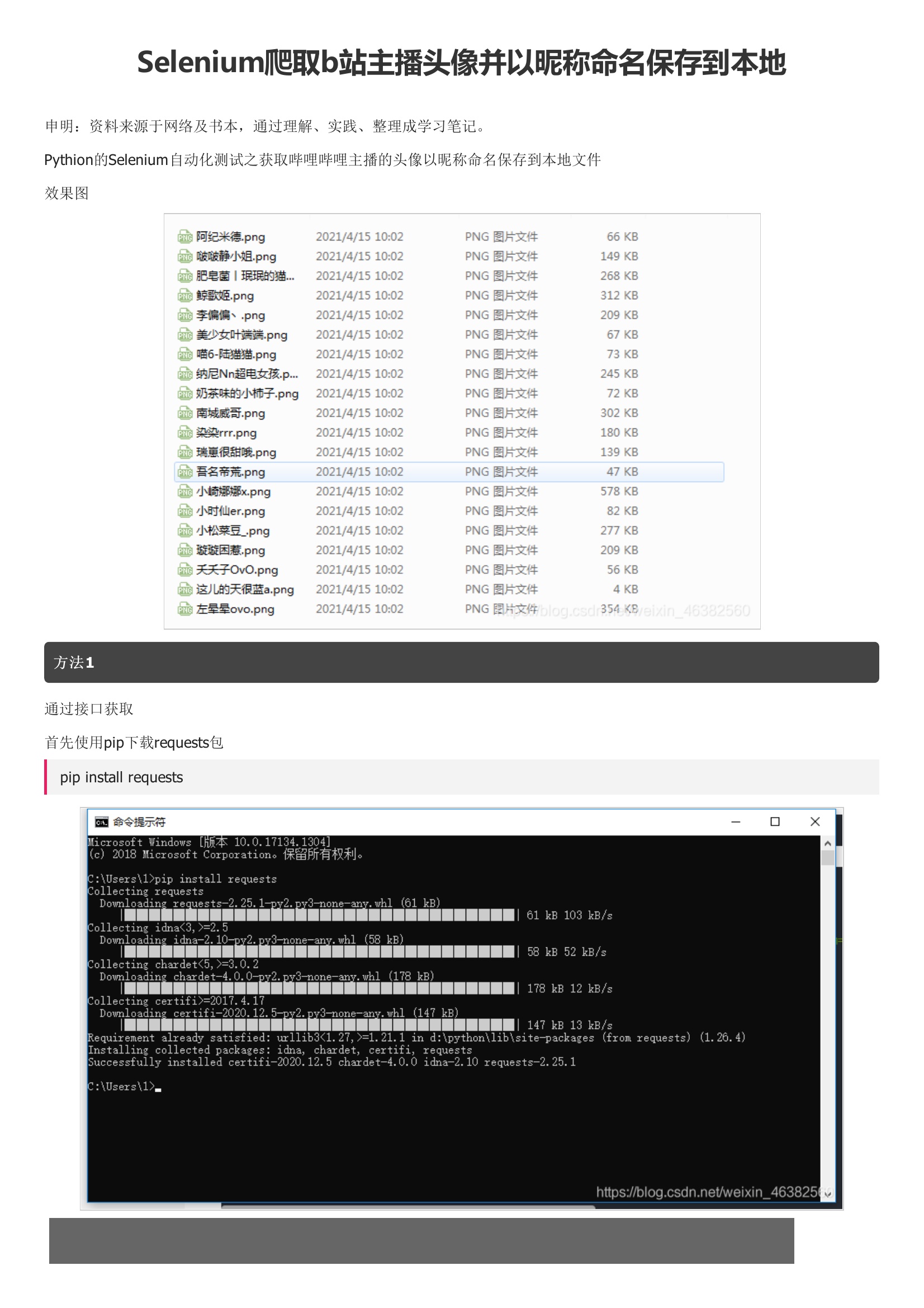
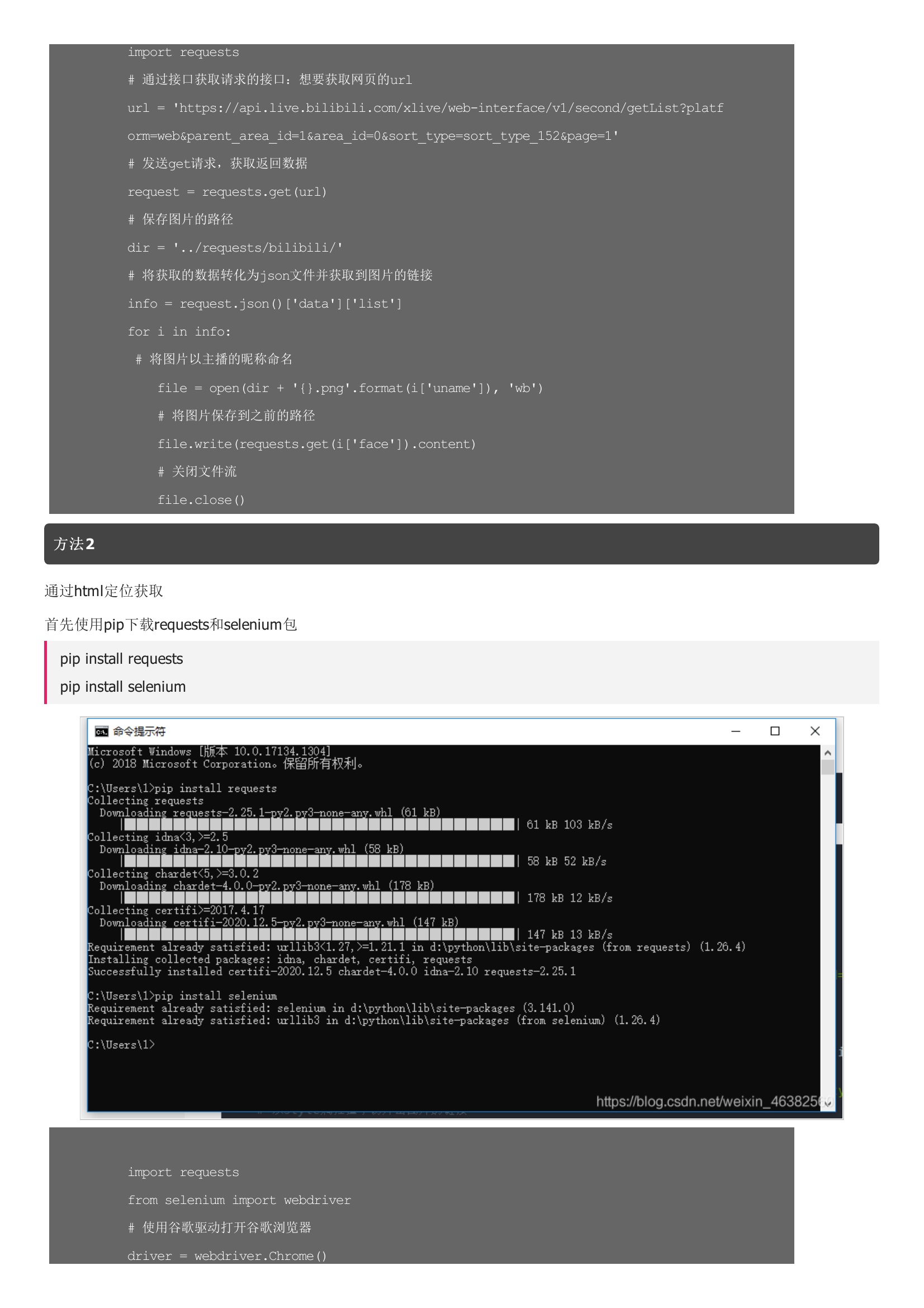
Pythion的Selenium自动化测试之获取哔哩哔哩主播的头像以昵称命名保存到本地文件效果图方法1通过接口获取首先使用pip下载requests包
暂无评论
flash as3.0做的拍照并保存到本地,必须连上摄像头
爬取各大招聘公司将招聘信息保存到本地.
听说取QQ昵称旧接口不能用了 所以我做了一个新的 当然我也是因为不能取QQ昵称才做的! 所以现在给你们用吧!
主要介绍了Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码,需要的朋友可以参考下
前言 莫名其妙博客不给通过,搞了好久避开各种词。谜一样的操作··· 前面已经写了两篇,都是用requests爬取页面,之前腾讯提供的接口用的json解析内容,丁香园则是直接用BeautifulSoup
主要给大家介绍了关于scrapy利用selenium爬取豆瓣阅读的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
主要为大家详细介绍了Python使用Selenium+BeautifulSoup爬取淘宝搜索页,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
今天小编就为大家分享一篇Scrapy基于selenium结合爬取淘宝的实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
主要介绍了基于python requests selenium爬取excel vba过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
自动爬取微信公众号历史所有文章以及封面图片Selenium+Chromedriver



暂无评论