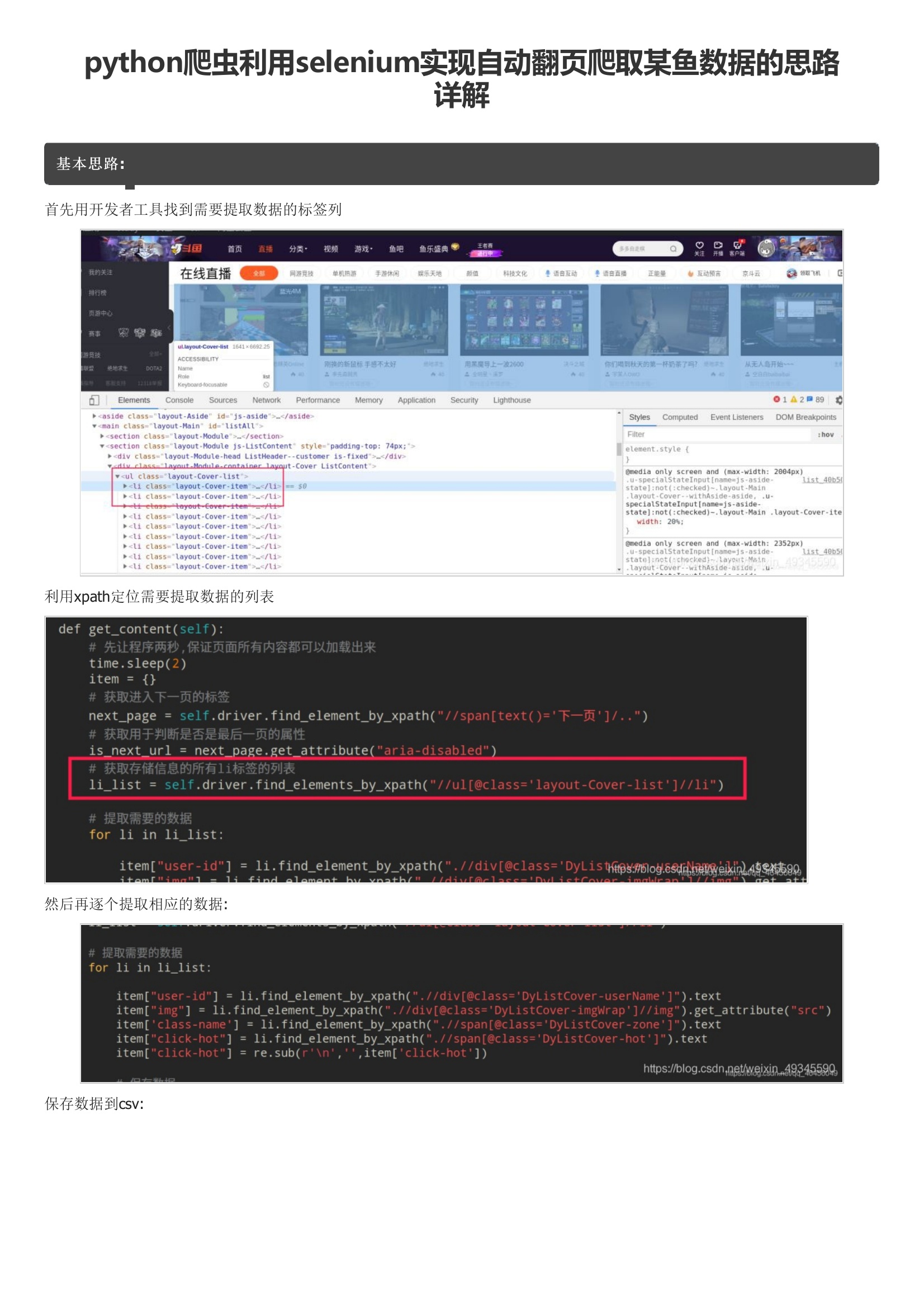
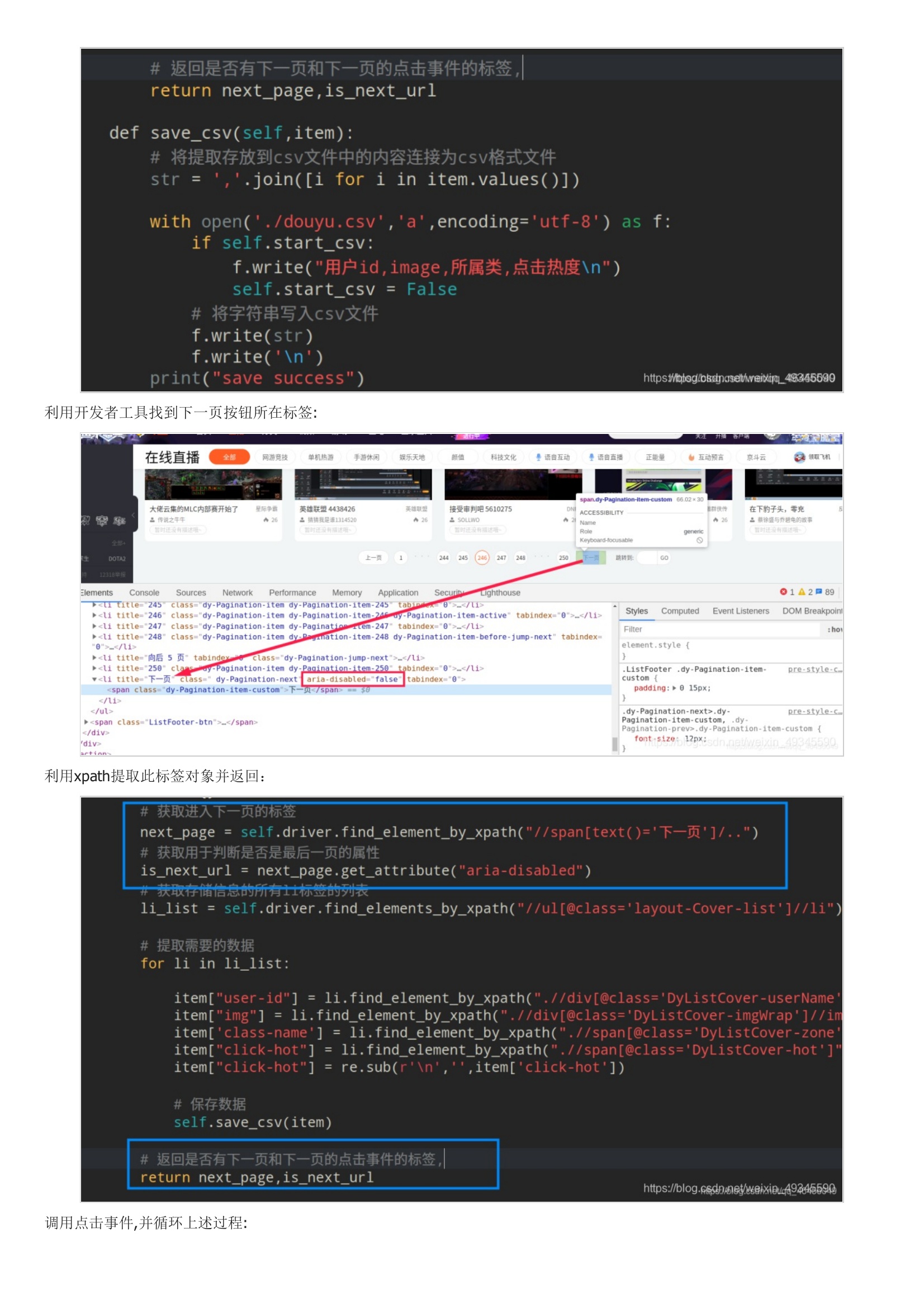
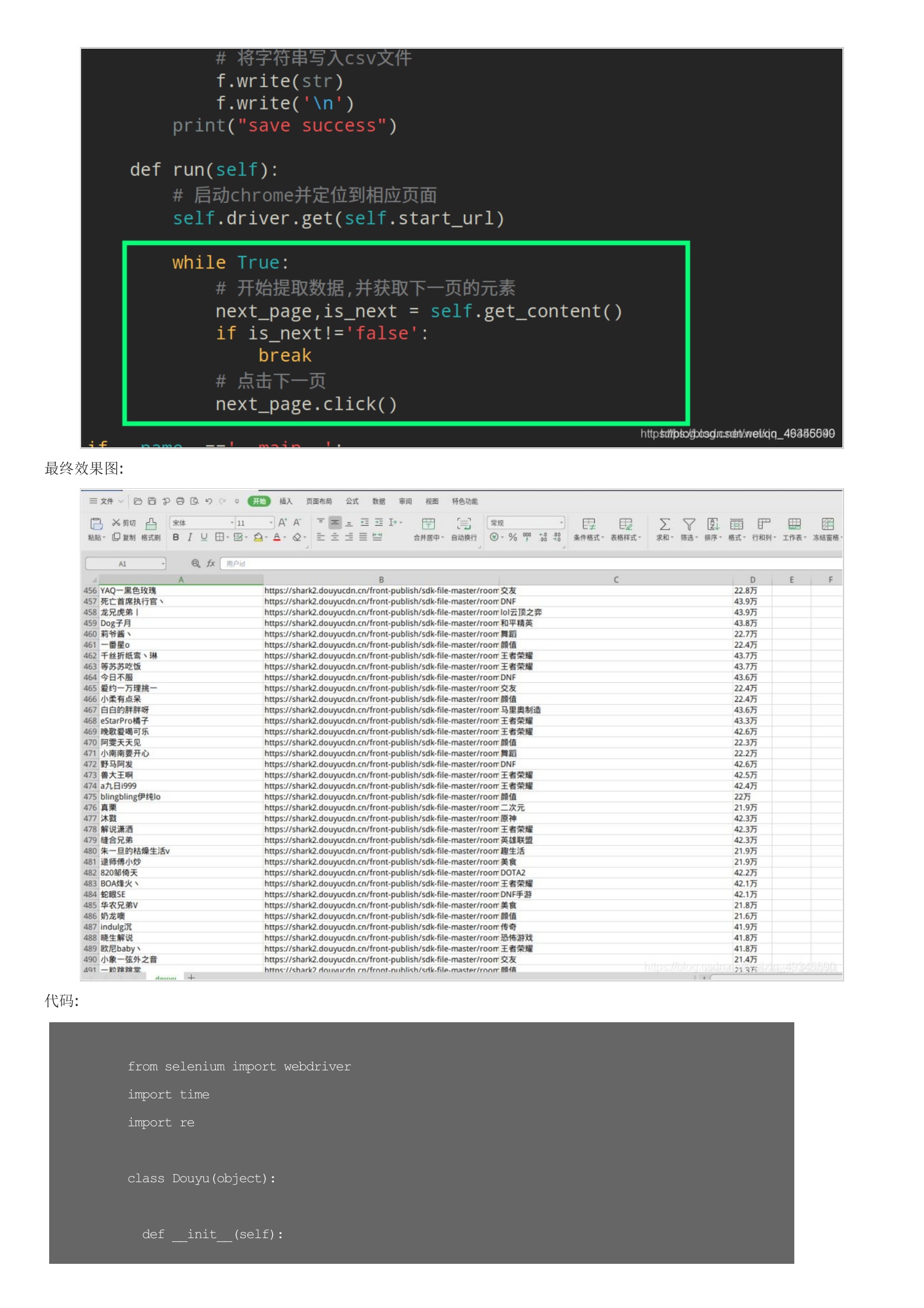
基本思路:首先用开发者工具找到需要提取数据的标签列利用xpath定位需要提取数据的列表然后再逐个提取相应的数据:保存数据到csv:利用开发者工具找到下一页按钮所在标签:利用xpath提取此标签对象并返回:调用点击事件,并循环上述过程:最终效果图:代码:
暂无评论
爬取百度图片的scrapy爬虫实现
本脚本可以自动化下载中国天气网上,每个城市的天气,风力风向以及最高气温最低气温等信息。下载本资源,直接安装所需的依赖,本地一定要建好指定的库表和字段,具体看代码,下载到数据库。
主要介绍了Python爬虫 scrapy框架爬取某招聘网存入mongodb解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
python selenium爬虫解决python作业爬取中国大学排名榜单result open data.xls w encoding utf8result.write大学名称t英
Python自动化办公爬虫指定文章的爬取方法,实现自动化爬取会计师协会网站的指定文章。Python语言优雅、简单,是自动化插件、网络爬虫、数值分析、科学计算、云计算等领域的重要工具。本文将为您介绍Py
Selenium支持很多浏览器,那么要选择哪个浏览器?选择哪个版本呢?小白建议用当然Chrome,并需要相应的驱动driver。 通过多进程爬取MAC地址,关键知识点是:selenium和多进程mul
啥都先不说,上代码: import requests, re, json, sqlite3, datetime, time class BilibiliRank: def __init__(self,
使用PythonScrapy框架爬取51Job职位信息,包括职位所在地、所属公司、薪酬、招聘需求、福利待遇等等。
本文详细介绍了Python爬虫的基本工作流程,包括发送请求、获取响应、解析内容和保存数据等步骤,并重点讲解了使用Requests库来实现HTTP请求的方法。对于初学者来说非常友好,能够快速入门爬虫技术
相信很多人都喜欢打篮球, 并且对自己喜欢的球星的比赛数据都很关注,于是我就想着去爬取篮球网站的数据。但是相对来说爬取一个数据也没啥挑战性,于是我又赶着学习了xlsxwriter模块,将爬取的的数据放入


暂无评论