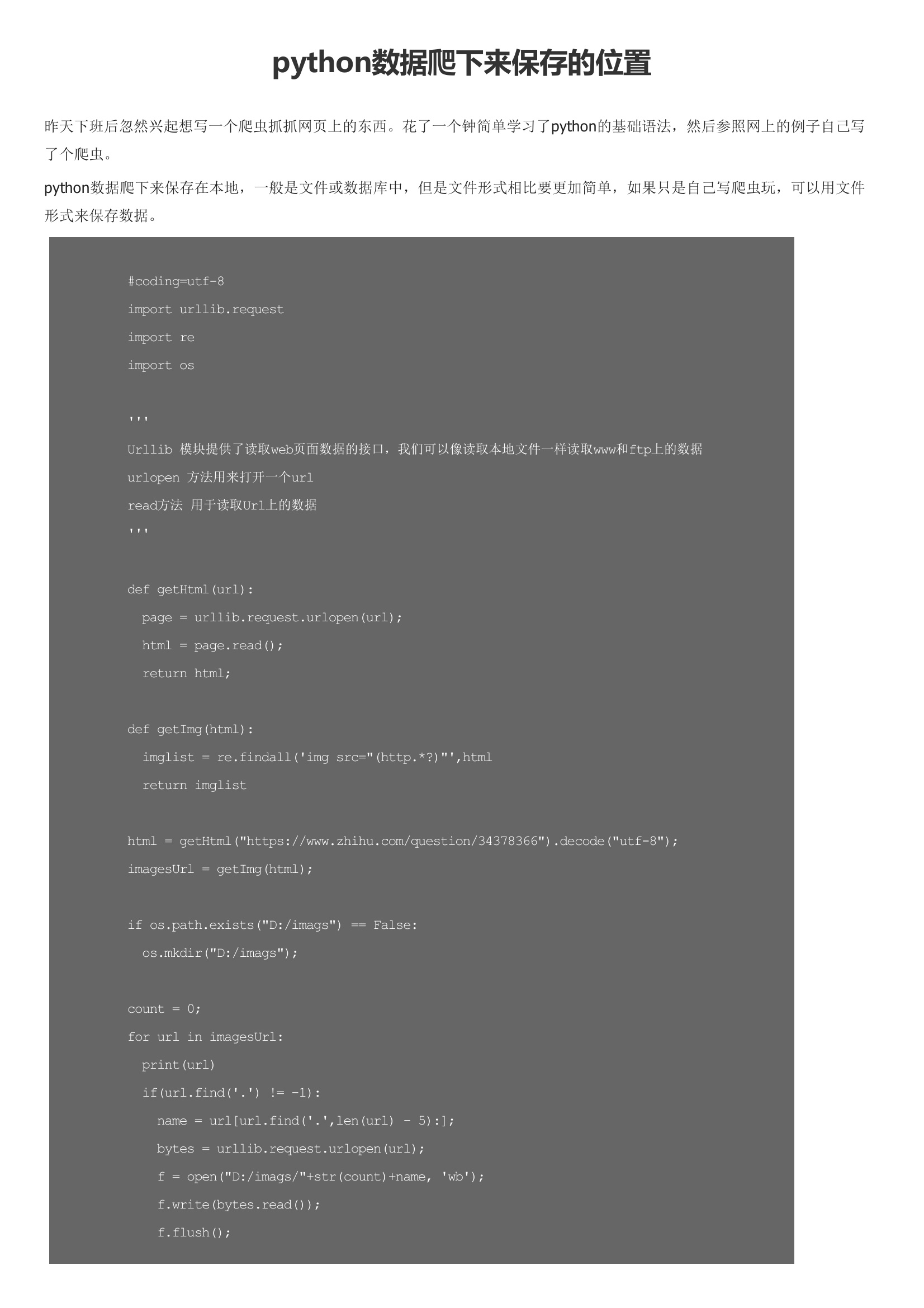
昨天下班后忽然兴起想写一个爬虫抓抓网页上的东西。花了一个钟简单学习了python的基础语法,然后参照网上的例子自己写了个爬虫。python数据爬下来保存在本地,一般是文件或数据库中,但是文件形式相比要更加简单,如果只是自己写爬虫玩,可以用文件形式来保存数据。经测试,基本功能还是可以实现的。花的较多的时间就是正则匹配哪里,因为自己对正则表达式也不是非常熟悉。注:上面的程序基于 python 3.5。python3 和 python2 还是有些区别的。我刚开始看基础语法的时候就栽了一些坑里。
暂无评论
本人快考四级了,顺便用python爬了四级的词汇,格式已经转好了,json形式,给各位网友随便用,希望大家四级一起过啊
NULL博文链接:https://key232323.iteye.com/blog/1779445
Qt-QML手册英文版(从官网爬下来的,亲自制作) python,c++都可以用的哦,是通用的
代码已开源可以到github上直接下载: https://github.com/ICEJM1020/StationMaster 开源中国工具网 http://tool.oschina.net 是一个对
TensorFlow-PythonApi中文版;内附英文对照版,用Google翻译亲自爬下来的,因为是机器翻译会有不准确的地方,但是日常应急已经够了童叟无欺;感谢(http://www.tensorf
体彩大乐透2007001至2019032所有中奖号、出球顺序、一二三等中奖数金额和追加数、金额均爬下来了。csv格式,方便导入mysql或用SPSS、excel分析。下面放上第一行。其中真红1-5表示
AVA数据集压缩文件中包含的是整个AVA数据集,在官网下载下来的都是文本,作者手写了一个程序将一个个图片爬下来,仅供大家参考学习,如果纰漏欢迎指出。
拖动并保存位置,记录在COOKIE中
recycleView交换item位置及保存交换后的位置
本篇文章主要介绍了详解docker pull 下来的镜像文件存放的位置,具有一定的参考价值,有兴趣的可以了解一下。

暂无评论