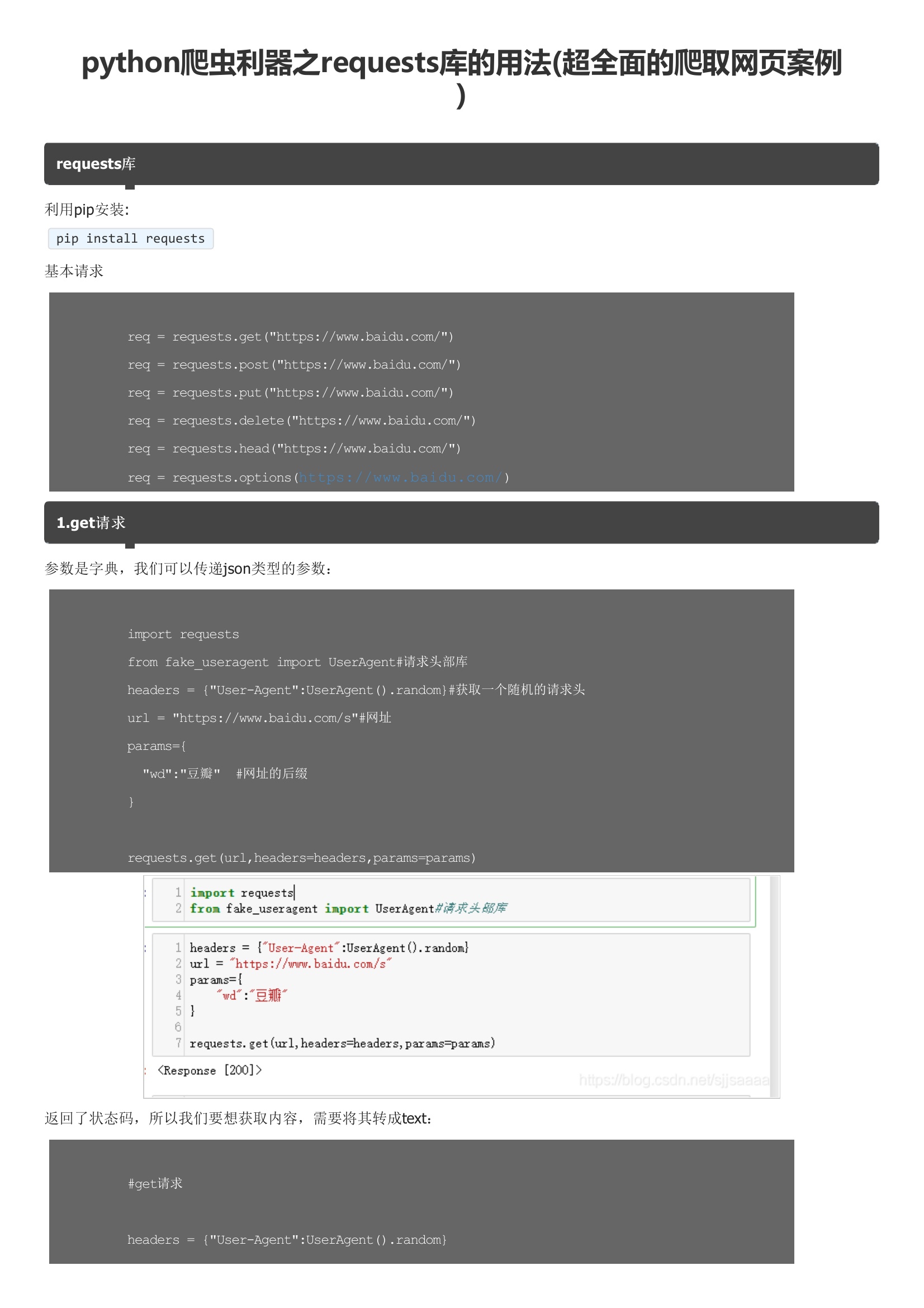
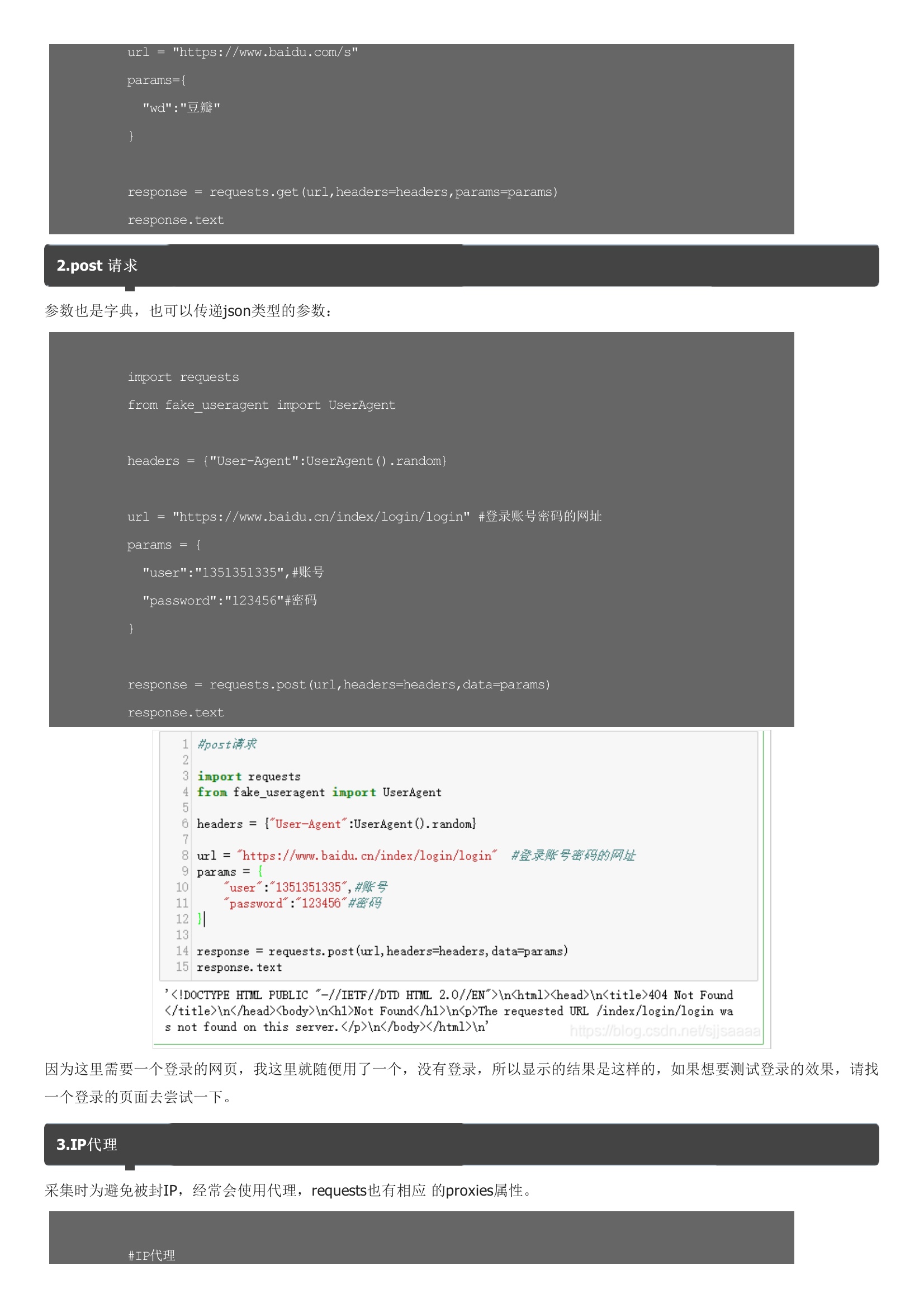
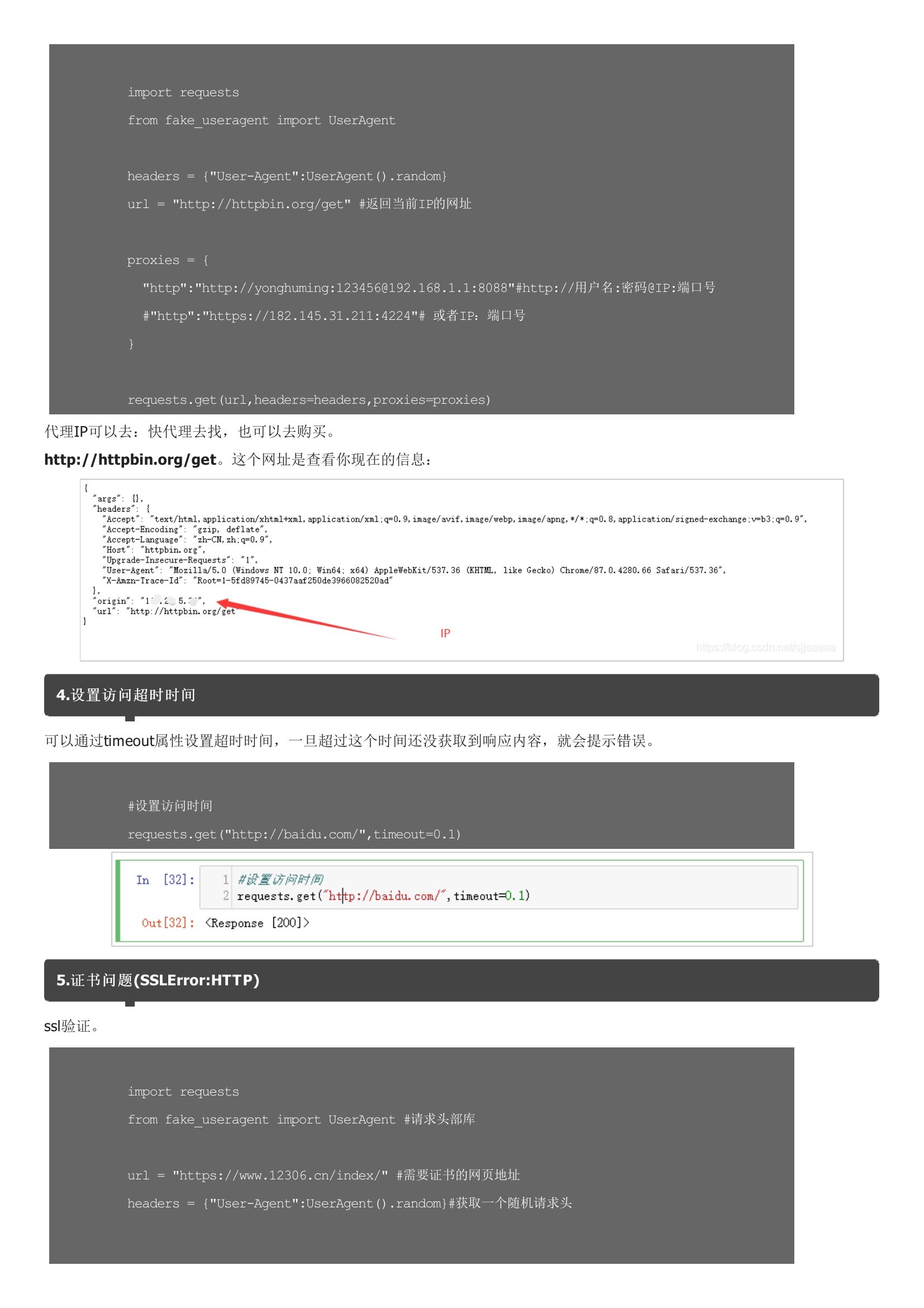
requests库利用pip安装:基本请求1.get请求参数是字典,我们可以传递json类型的参数:返回了状态码,所以我们要想获取内容,需要将其转成text:2.post 请求参数也是字典,也可以传递json类型的参数:因为这里需要一个登录的网页,我这里就随便用了一个,没有登录,所以显示的结果是这样的,如果想要测试登录的效果,请找一个登录的页面去尝试一下。代理IP可以去:快代理去找,也可以去购买。
暂无评论
获取某个网页 import requests r = requests. get('https://www.baidu.com/') print(type(r)) print(r. status_co
爬图片,主要正则匹配到的url也不是真正的视频地址,打开那个视频url后你会发现浏览器地址栏上的地址变了,最好用mitmproxy抓包手机上的视频链接,那个链接才是真正的视频地址,而且没有水印的哦
利用Python爬虫requests+BeautifulSoup实现丁香营销师招聘爬取
主要介绍了Python Requests库基本用法,结合实例形式总结分析了Python Requests库安装、请求发送与响应、文件下载、重定向等相关操作技巧及注意事项,需要的朋友可以参考下
主要介绍了Python requests库用法,结合实例形式分析了Request库的功能、安装、请求创建、响应等相关操作技巧,需要的朋友可以参考下
主要介绍了python面向对象多线程爬虫爬取搜狐页面的实例代码,需要的朋友可以参考下
python爬虫-梨视频短视频爬取(线程池)示例代码梨视频示例:Ctrl+Alt+L格式化代码
最近在学习python3,下面这篇文章主要给大家介绍了关于Python3实战爬虫之爬取京东图书图片的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下
文章目录一、pyhton连接mysql数据库二、用xpath抓取有用信息说几个比较容易掉坑的地方一二三效果 一、pyhton连接mysql数据库 我是写了一个py文件来封装一下,然后在爬取猫眼的py文
2020年3月14日 任务介绍 此次爬虫任务为“爬取新房销售信息”,获取楼盘名、地址、价格的简单信息,我选取的城市是“赣州”,尝试过安居客、房天下等几个房屋信息网站,安居客有反爬措施,由于是新手比较怂



暂无评论