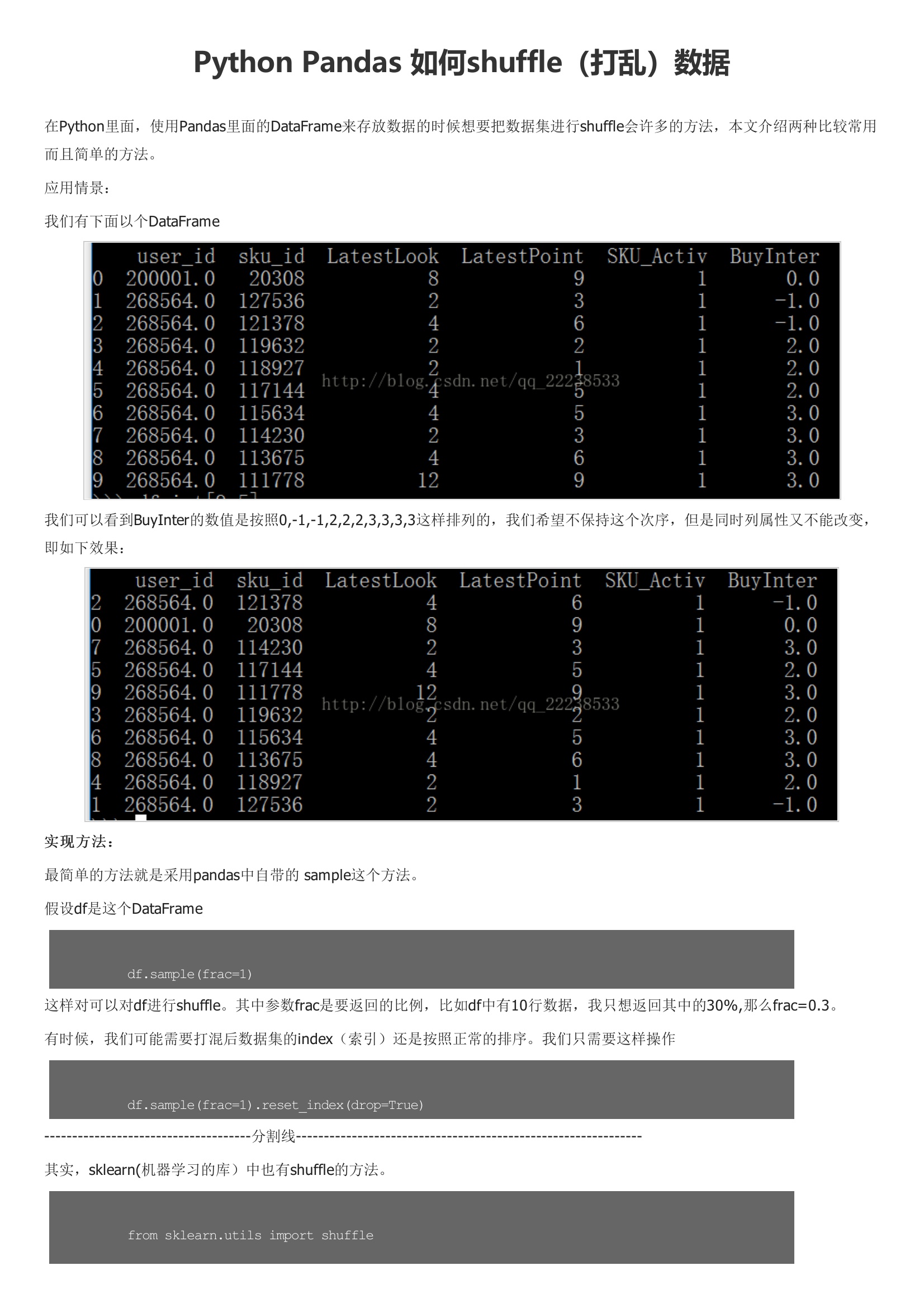
在Python里面,使用Pandas里面的DataFrame来存放数据的时候想要把数据集进行shuffle会许多的方法,本文介绍两种比较常用而且简单的方法。应用情景:我们有下面以个DataFrame我们可以看到BuyInter的数值是按照0,-1,-1,2,2,2,3,3,3,3这样排列的,我们希望不保持这个次序,但是同时列属性又不能改变,即如下效果:最简单的方法就是采用pandas中自带的 sample这个方法。假设df是这个DataFrame这样对可以对df进行shuffle。其中参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3。有时候,我们可能需要打混后数据集的index(索引)还是按照正常的排序。我们只需要这样操作-------------------------------------分割线--------------------------------------------------------------其实,sklearn中也有shuffle的方法。另外,numpy库中也有进行shuffle的方法(不建议)

暂无评论