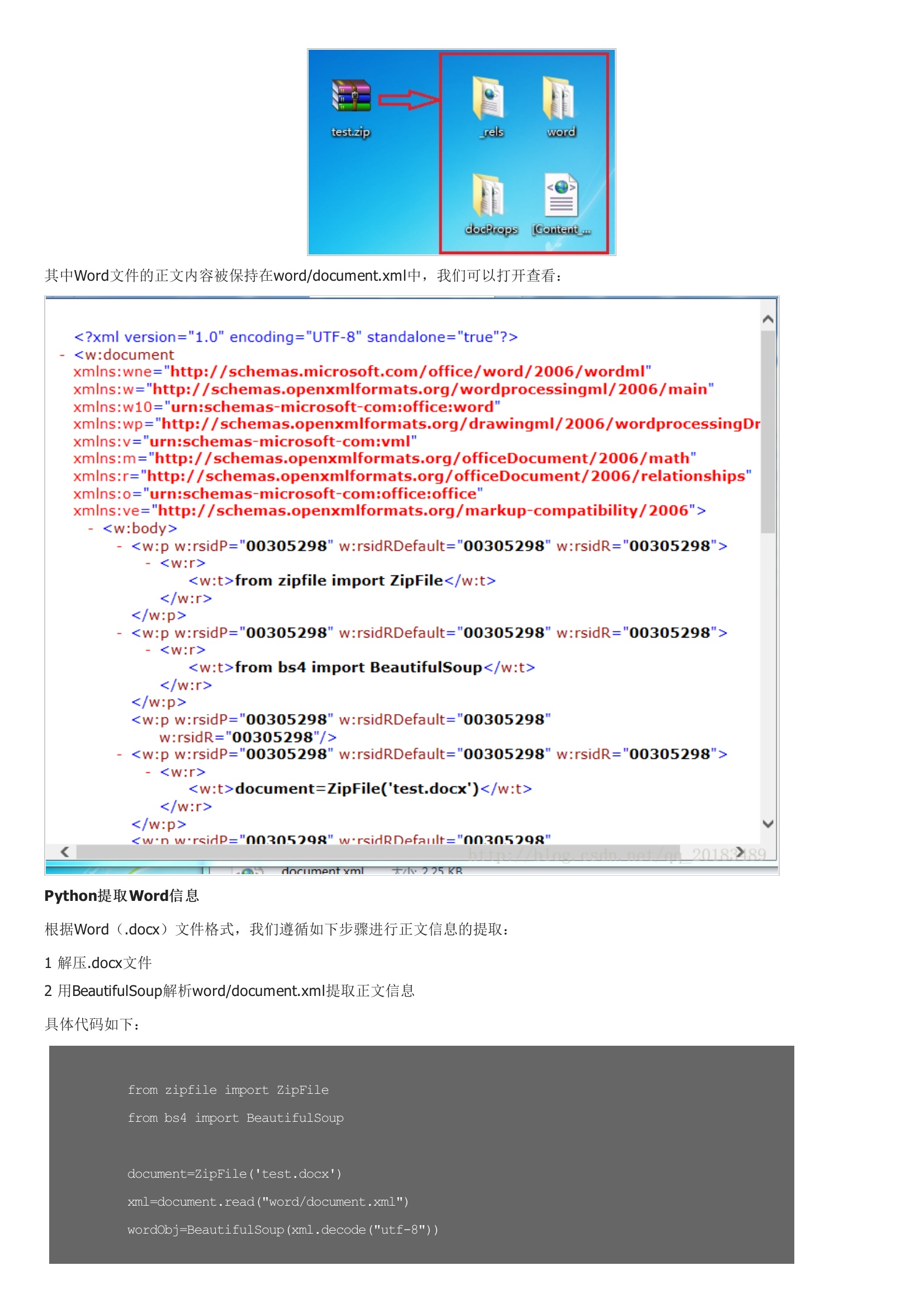
本文介绍用Python简单读取*.docx文件信息,一些python-word库就是对这种方法的扩展。大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容。其内容如下:改变其后缀名为test.zip,然后解压,会得到如下文件:其中Word文件的正文内容被保持在word/document.xml中,我们可以打开查看:根据Word文件格式,我们遵循如下步骤进行正文信息的提取: 1 解压.docx文件 具体代码如下:
暂无评论
主要为大家详细介绍了Python读取Word(.docx)正文信息的方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
修改下地址就可以读取word文本内容,需要先行安装相应库
这是一个Python自动办公的源码实例,可以直接运行。源码演示了如何使用Python编程语言读取和处理Word文档文件。通过这个源码文件,你可以学习如何使用Python实现自动化办公功能,并且可以将其
本文是利用Python脚本读取图片信息,有几个说明如下: 1、没有实现错误处理 2、没有读取所有信息,大概只有 GPS 信息、图片分辨率、图片像素、设备商、拍摄设备等 3
今天小编就为大家分享一篇Python使用pyshp库读取shapefile信息的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
为了把自然语言处理技术有效的运用到网页文档中,本文提出了一种依靠统计信息,从中文新闻类 网页中抽取正文内容的方法。该方法先根据网页中的HTML 标记把网页表示成一棵树,然后利用树中每个 结点包含的中文
.
# -*- coding:utf-8 -*-
主要介绍了Python读取word文本操作详解,介绍了涉及到的模块,相关概念,模块的安装等内容,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下
关键点在于邮件正文转html图片保存到word中还带上取附件,压缩邮件文件

暂无评论