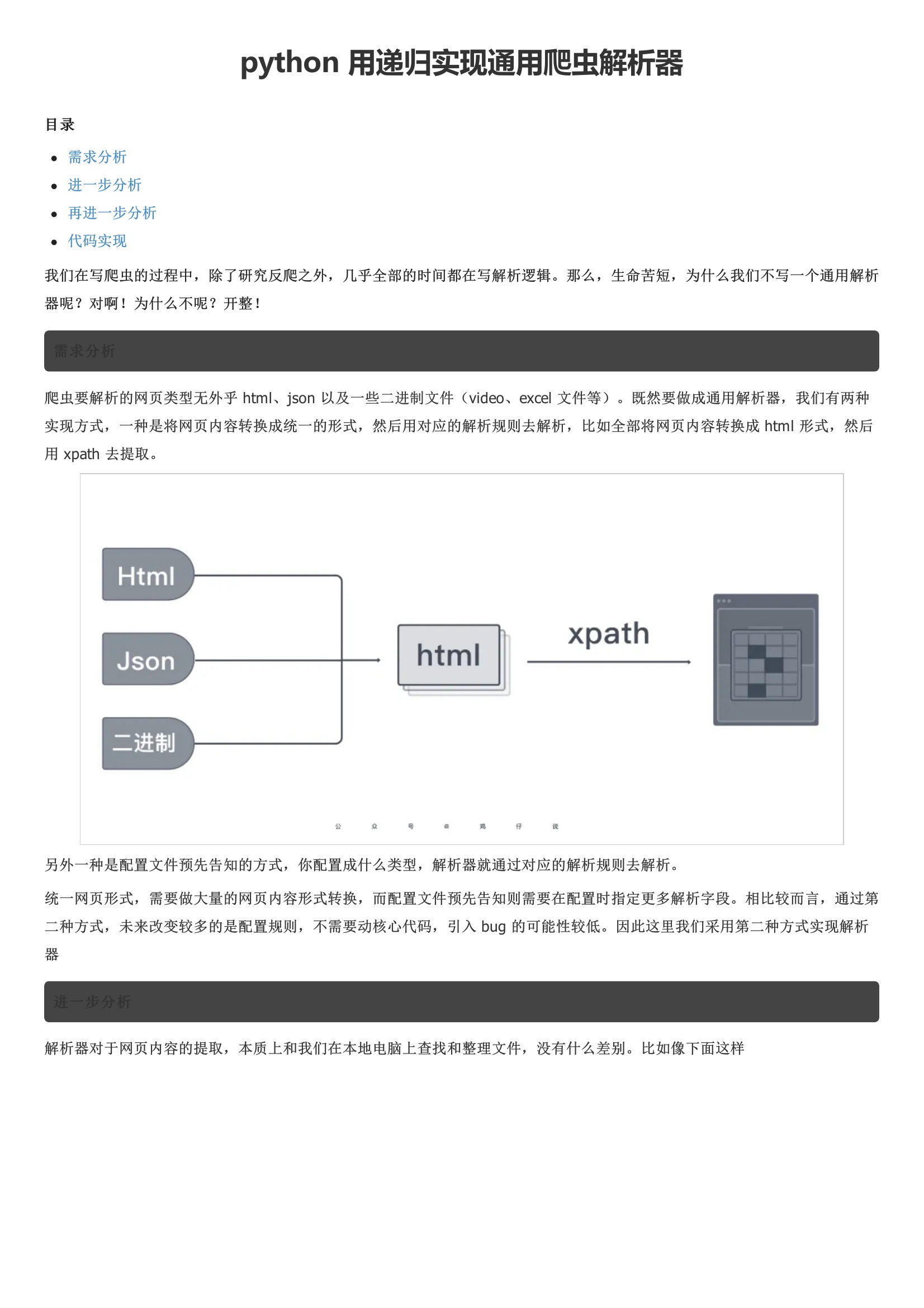
需求分析爬虫要解析的网页类型无外乎 html、json 以及一些二进制文件。既然要做成通用解析器,我们有两种实现方式,一种是将网页内容转换成统一的形式,然后用对应的解析规则去解析,比如全部将网页内容转换成 html 形式,然后用 xpath 去提取。统一网页形式,需要做大量的网页内容形式转换,而配置文件预先告知则需要在配置时指定更多解析字段。相比较而言,通过第二种方式,未来改变较多的是配置规则,不需要动核心代码,引入 bug 的可能性较低。而针对有列表层级的网页可能还涉及递归遍历问题。很简单,将解析方式改为 xpath 对象,然后传入 xpath 解析语法即可。案例中仅实现了对于 json 的支持,小伙伴可以基于自己的项目,改造成其他的解析形式。





暂无评论