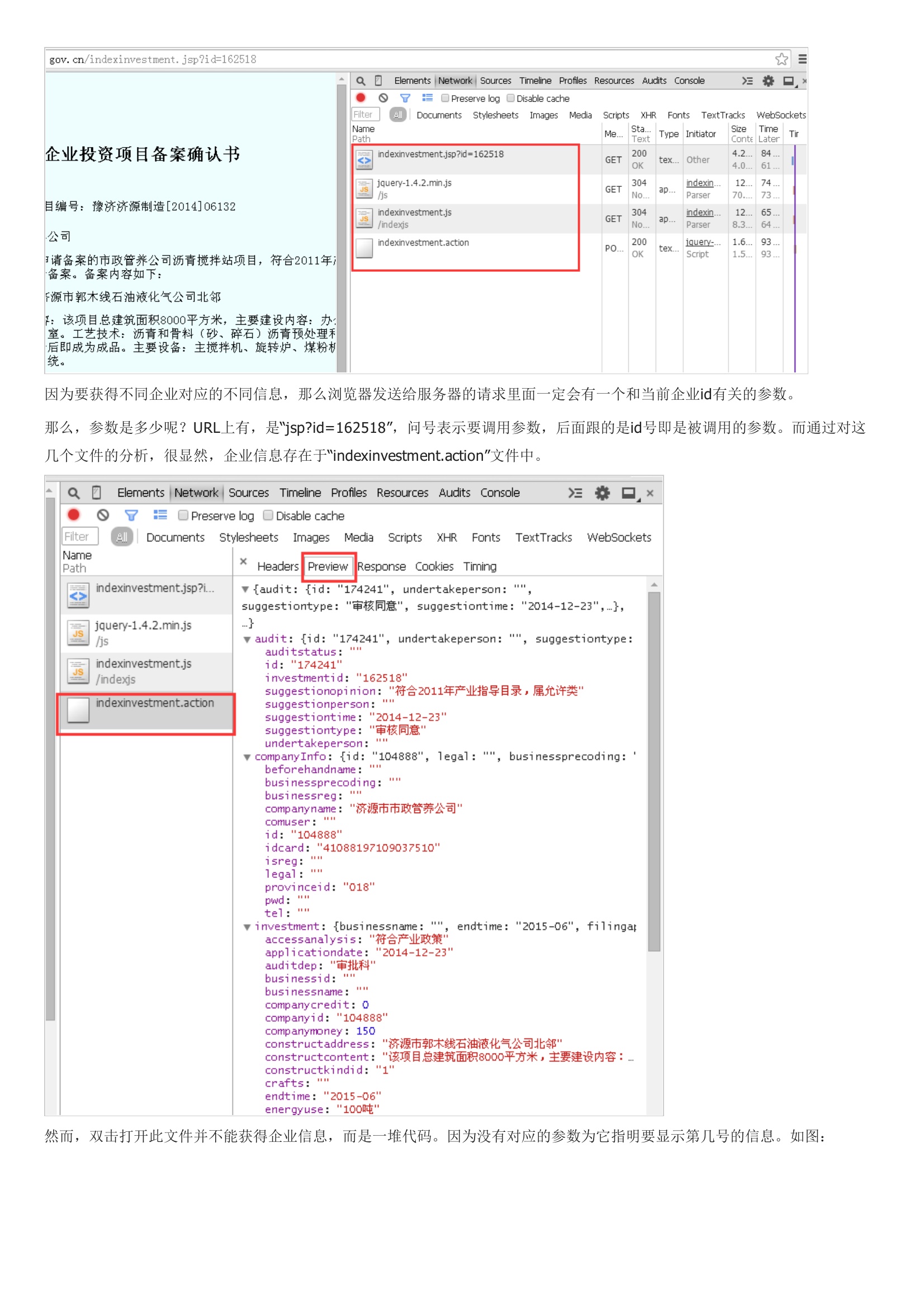
用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字。可以利用Chrome的“开发者工具”来寻找谁是真正的内容提供者。打开Chrome浏览器,按下键盘F12即可呼出此工具。因为要获得不同企业对应的不同信息,那么浏览器发送给服务器的请求里面一定会有一个和当前企业id有关的参数。而通过对这几个文件的分析,很显然,企业信息存在于“indexinvestment.action”文件中。因为没有对应的参数为它指明要显示第几号的信息。是因为响应回来的内容与浏览器默认的编码方式不同。再然后使用for、while等循环,批量获取这些《备案书》。




暂无评论