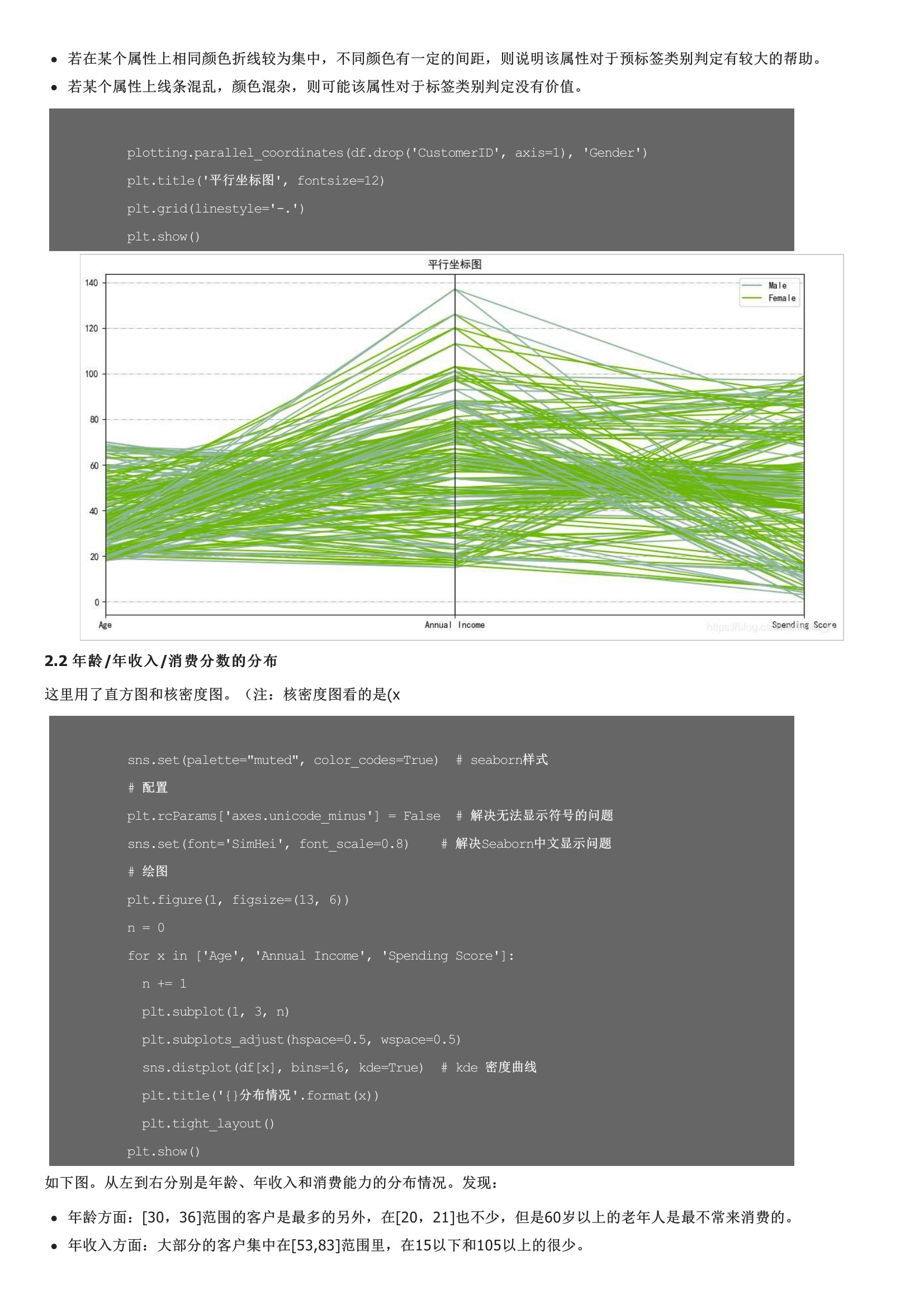
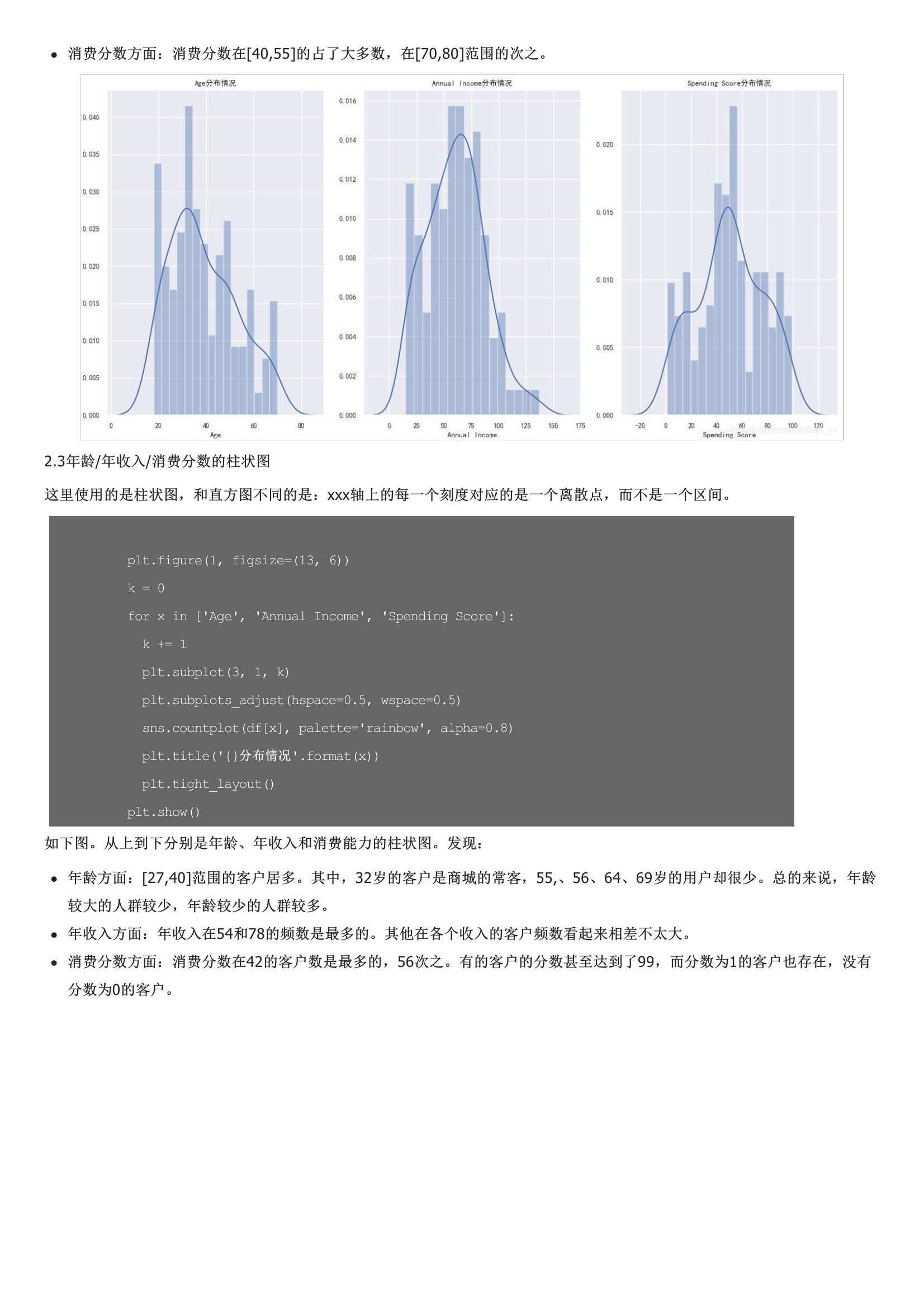
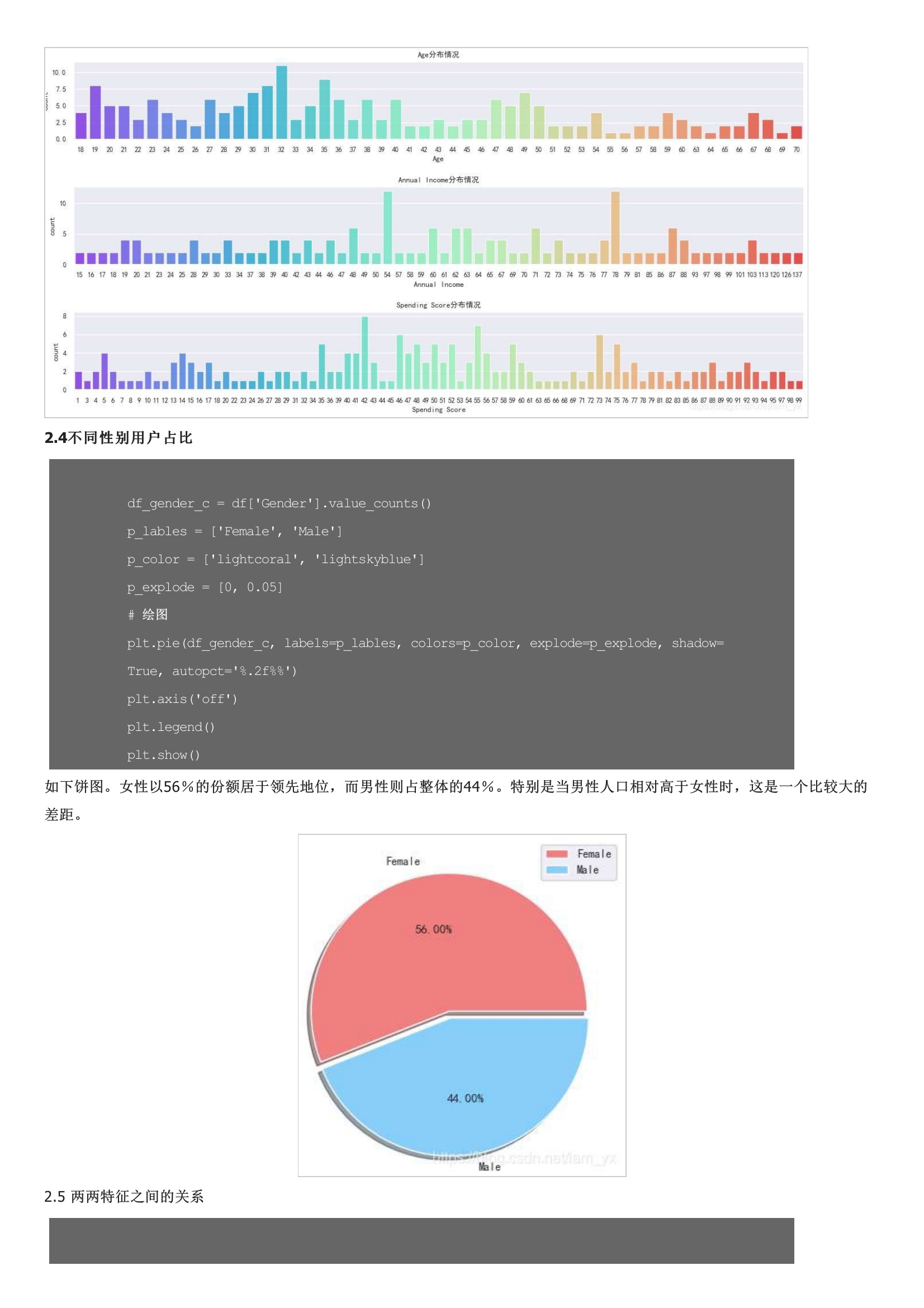
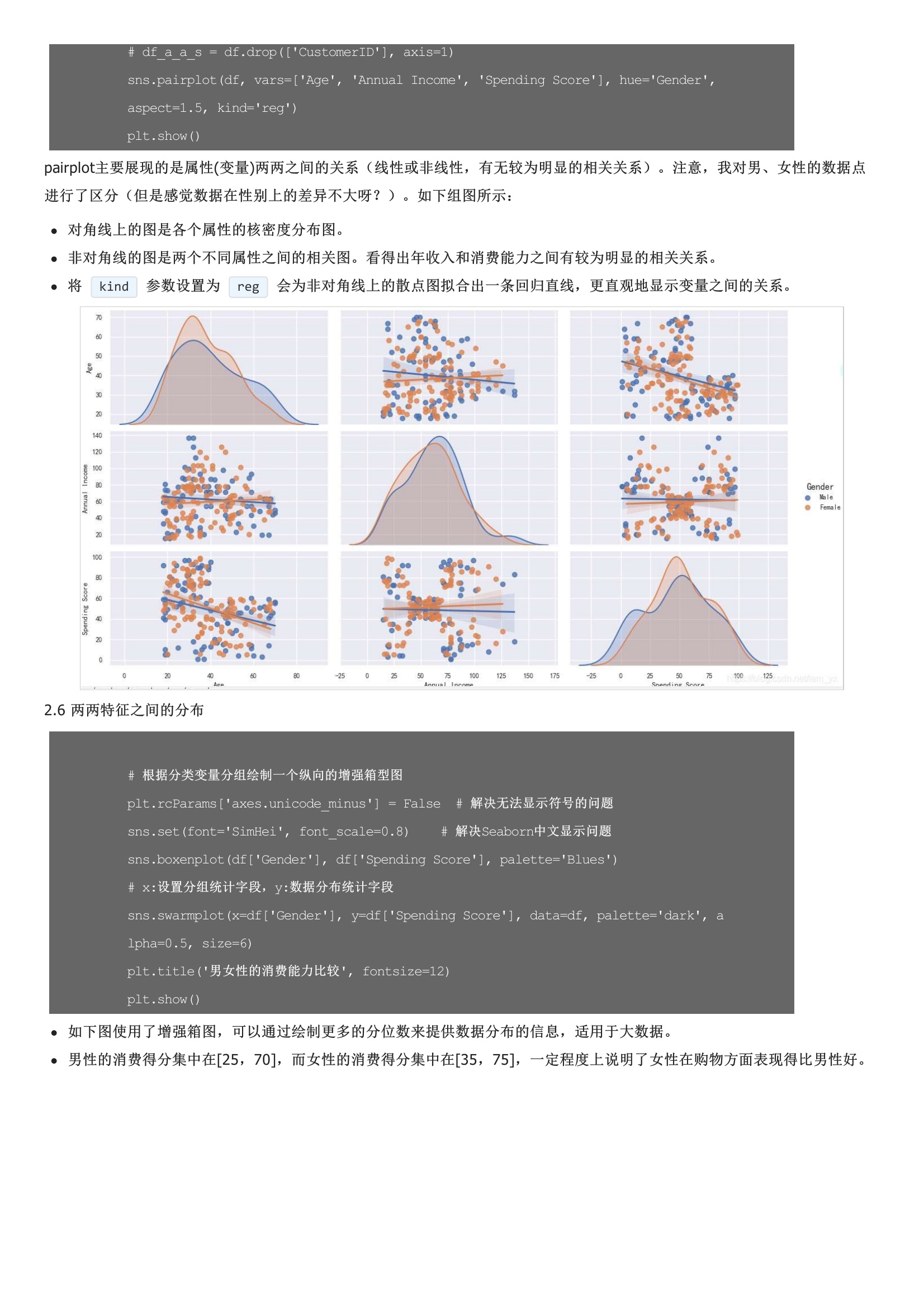
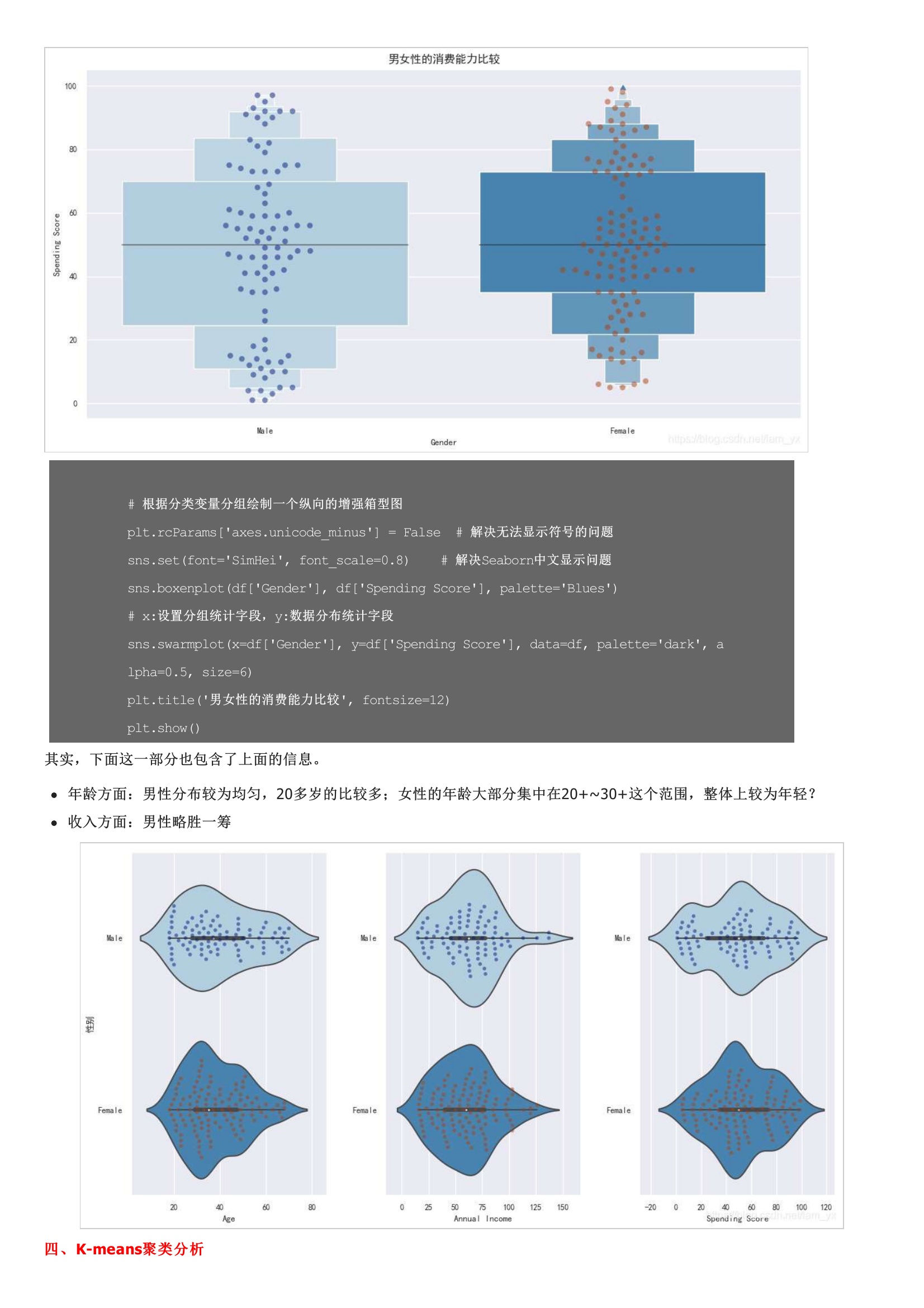
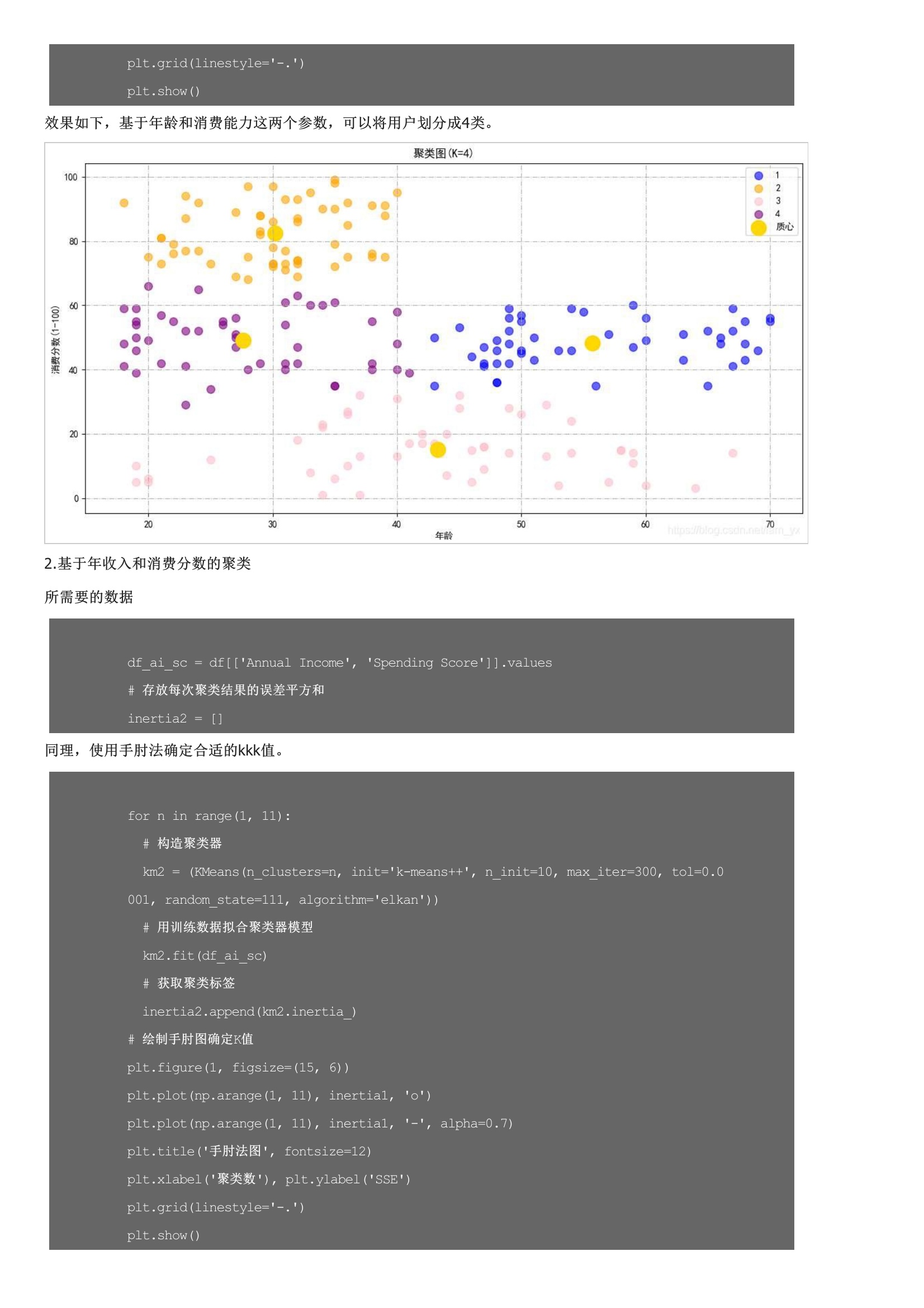
从左到右分别是年龄、年收入和消费能力的分布情况。女性以56%的份额居于领先地位,而男性则占整体的44%。特别是当男性人口相对高于女性时,这是一个比较大的差距。注意,我对男、女性的数据点进行了区分(但是感觉数据在性别上的差异不大呀?其实,下面这一部分也包含了上面的信息。核心指标误差平方和是所有样本的聚类误差反映了聚类效果的好坏,公式如下:核心思想
暂无评论
%k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足: %同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获
VC实现的K-Means动态聚类算法源程序,可以学习学习
java程序,通过给定的源数据,通过k-means实现聚类,有界面。
介绍C++实现K-means聚类算法的源码和文档下载,让你快速了解该算法并进行实现。K-means聚类算法是一种常用的数据挖掘算法,能够将数据自动分组,有广泛的应用。本资源包括源代码和详细文档,帮助你
Power BI K-Means聚类插件1.0.1版是一款专业的数据可视化工具,为用户提供了先进的聚类分析功能。该插件采用了K-Means算法,可以帮助用户更加深入地挖掘数据中的潜在关联和规律。在Po
分层聚类算法的优点在于它可以在不同粒度上对数据进行探测, 然而一旦出现一组对象合并时, 类之间就不能交换对象, 因此在合并前, 必须花费大量时间计算单链接距离( 或全链接距离)
上述代码是利用python内置的k-means聚类算法对鸢尾花数据的聚类效果展示,注意在运行该代码时需要采用pip或者其他方式为自己的python安装sklearn以及iris扩展包,其中X=iris
这是一个有关于聚类算法的ppt讲义,里面有涉及到常见的EM算法和K平均值算法
用matlab仿真实现的K-MEANS改进聚类,可以运行
```python # k means教程代码(聚类) # 0.引入依赖 import numpy as np import matplotlib.pyplot as plt # 从sklearn中直





暂无评论