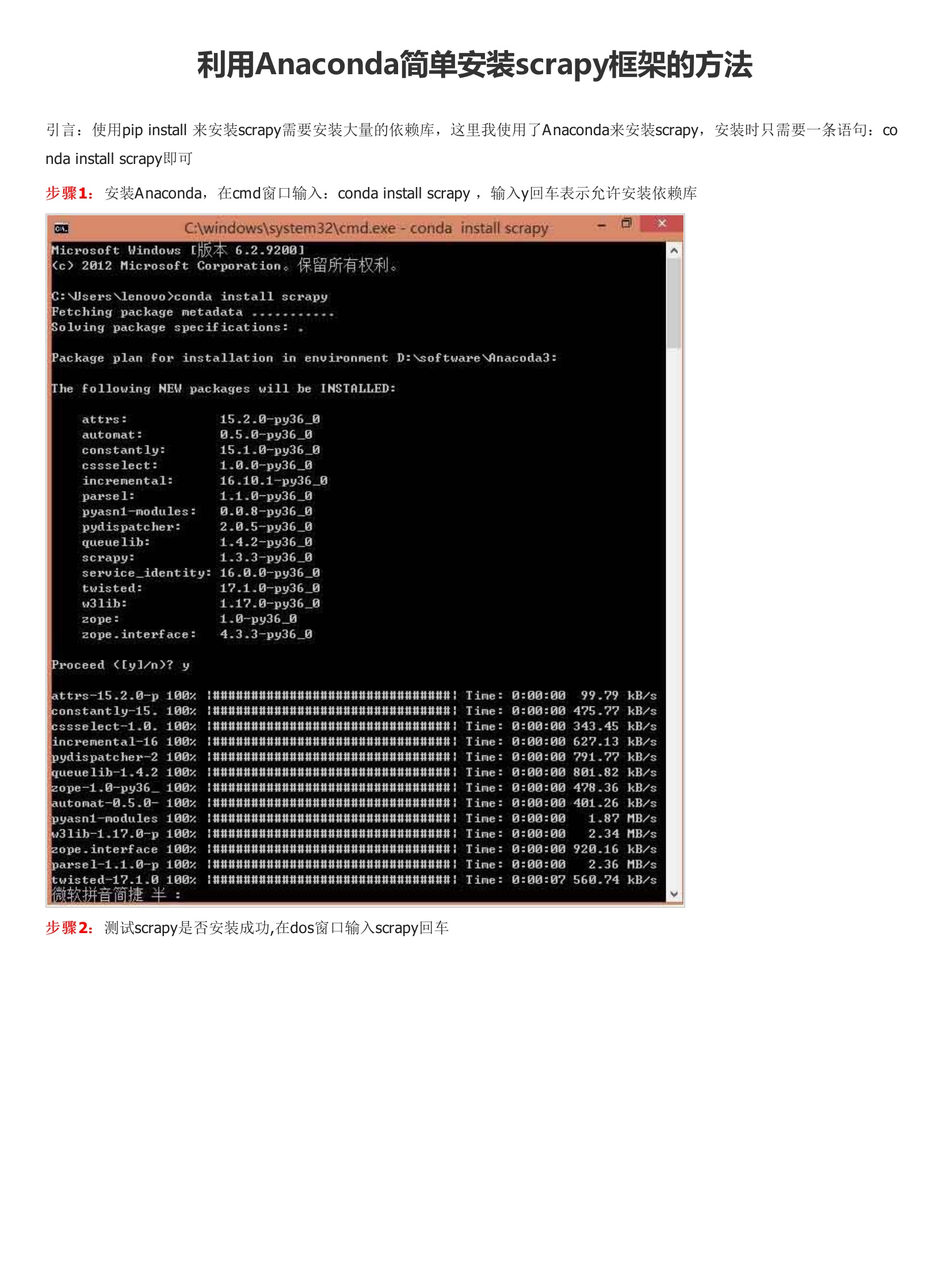
引言:使用pip install 来安装scrapy需要安装大量的依赖库,这里我使用了Anaconda来安装scrapy,安装时只需要一条语句:conda install scrapy即可万一它让你更新一大堆库的话,反正我是等他更新完了........
暂无评论
一本讲解python爬虫框架scrapy的书籍,对需要进行深入的朋友来说有很大的用处,结合官方文档来看如虎添翼,而且可以学习作者的思路。
PythonScrapy爬虫框架整个学习demo,包括后端数据库等逻辑的一些代码
五个基于scrapy框架的实实例1.爬取当当网书籍(包含3个)2.爬取天涯论坛的大宗师小说3.爬取百度的热点
爬虫scrapy框架小实例,在dos窗口项目所在目录,使用scrapy crawl basic 直接爬取,显示内容和网站的内容一样。
使用了python非常火的Scrapy框架写的爬虫项目,采用Scrapy自带的异步下载,实现对表情包网站的表情秒下载,相比于我上一个发布的表情包爬虫资源,整整快了100倍
利用scrapy写一个爬虫程序,来爬小姐姐的图片,基于python语言,开发软件pycharm,scrapy库的使用
scrapy是一个基于Twisted的异步处理框架,可扩展性很强。优点此处不再一一赘述。 下面介绍一些概念性知识,帮助大家理解scrapy。 一、数据流向 要想熟练掌握这个框架,一定要明白数据的流向是
有的可能不需要,不用管它
利用scrapy框架,构建的一个python语言爬虫,爬取信息为文字信息,最后存储在mysql数据库中(仅包含python代码部分)
scrapy是用python开发的爬虫框架,从网上查了安装方法,感觉都说的挺复杂,而且很多教程都很有年头了,于是记录了自己的安装过程。 首先安装python,地址:https://www.python


暂无评论