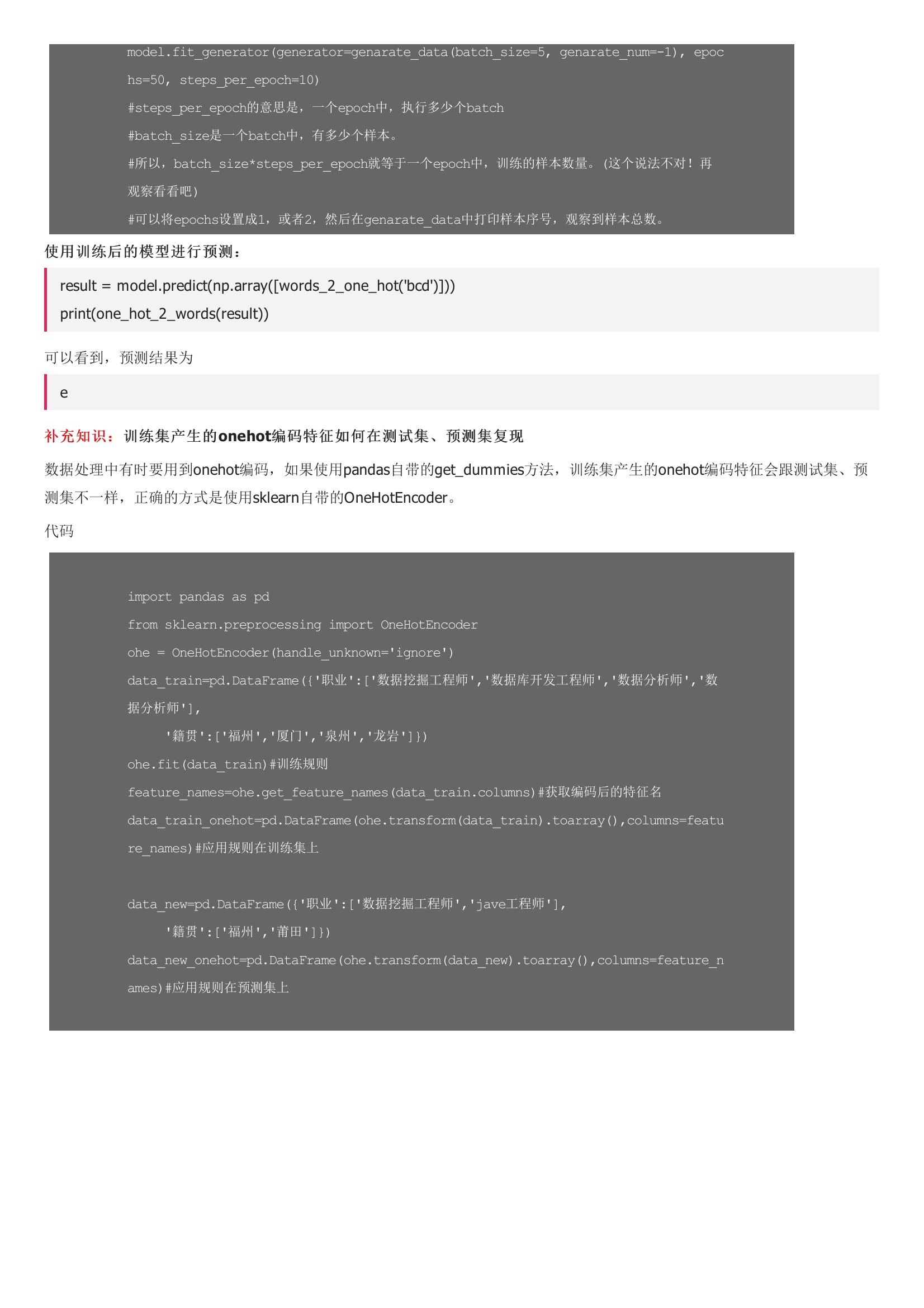
简单的LSTM问题,能够预测一句话的下一个字词是什么固定长度的句子,一个句子有3个词。数据处理中有时要用到onehot编码,如果使用pandas自带的get_dummies方法,训练集产生的onehot编码特征会跟测试集、预测集不一样,正确的方式是使用sklearn自带的OneHotEncoder。
暂无评论
使用双隐层LSTM模型(DHLSTM)和双向LSTM(Bi-LSTM)模型两种方法,实现MNIST数据集分类
TCC LSTM Python项目
<ol><li>如何诊断和调整LSTM</li></ol>LSTM模型的调参是深度学习过程中至关重要的一步。调参的核心目标是通过调整超参数提升模型
主要长短记忆神经在语音识别上的应用 。。。。。。。。。。
LSTM
交叉熵损失函数PyTorch中标准交叉熵误差损失函数的实现one hot形式和标签形式
1.什么是Keras? 如果说 Tensorflow 或者 Theano 神经网络方面的巨人. 那 Keras 就是站在巨人肩膀上的人. Keras 是一个兼容 Theano 和 Tensorflow
简介hotdisk的工作原理以及偏差纠正
http://apress.com/book/view/9781430225997iPhonegamesarehot!Justlookatthenumbers.Gamesmakeupover25per
我用过的最好用的热键软件,从97-2008



暂无评论