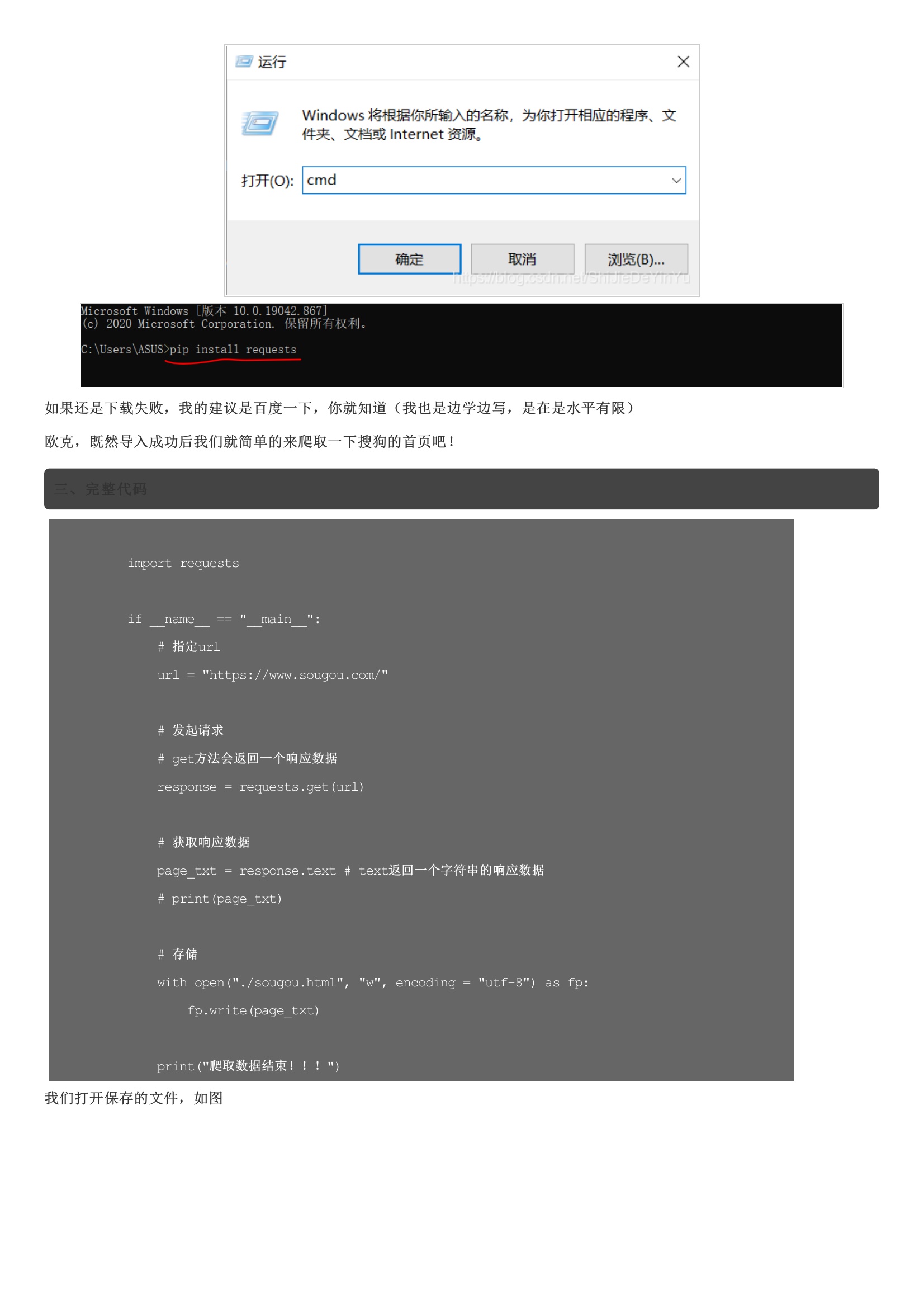
requests 模块的请求一般为 get 和 post3.将爬取的数据存储二、requests模块的导入因为 requests 模块属于外部库,所以需要我们自己导入库导入的步骤:1.右键Windows图标2.点击“运行”3.输入“cmd”打开命令面板4.输入“pip install requests”,等待下载完成如图:如果还是下载失败,我的建议是百度一下,你就知道欧克,既然导入成功后我们就简单的来爬取一下搜狗的首页吧!
暂无评论
python爬虫之爬取谷歌趋势数据
今天就和大家一起来讨论一下python实现12306余票查询,一起来感受一下python爬虫的简单实践我们说先在浏览器中打开开发者工具,尝试一次余票的查询,通过开发者工具查看发出请求的包余票查询界面可
1.Xpath Xpath是一门在XML中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。XQuery和xpoint都是构建于xpath表达之上 2.节点 父(parent),子(child
因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例。以后的重点会在 xpath 上。因为本人水平有限,所以如果出现报错,兄弟们还是百度一下好啦。
主要介绍了python爬虫 urllib模块url编码处理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
这个是对python爬虫re模块的简单介绍以及对Top250电影数据的爬取实战
该资源包含了Python网络编程和爬虫模块的学习大纲,其中包括了scapy、request、urllib、socket等模块的详细介绍,适合刚刚接触网络编程和爬虫的初学者学习。本资源将带领你深度了解P
函数简介 # 比如有如下三行代码,这三行代码是一个完整的功能 # print('Hello') # print('你好') # print('再见') # 定义一个函数 def fn() : prin
python基础之对象.zip
主要介绍了Python3爬虫学习之爬虫利器Beautiful Soup用法,结合实例形式分析了Beautiful Soup的功能、使用方法及相关操作注意事项,需要的朋友可以参考下


暂无评论